



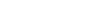
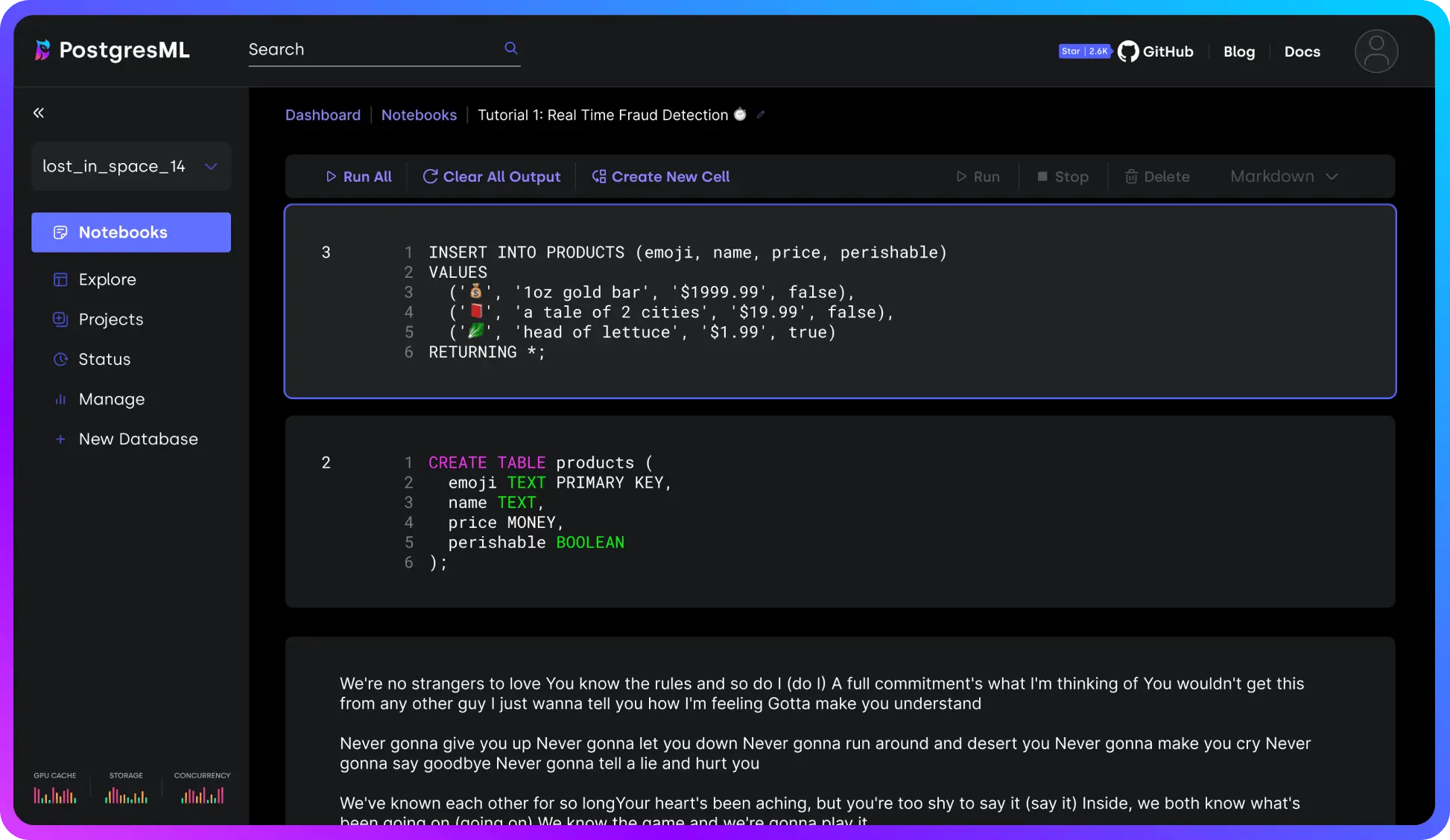
"Bleeding edge stuff in
a
matter of minutes."

Stuck with an AI stack so complicated your app barely runs in prod?🤔
Microservice mayhem
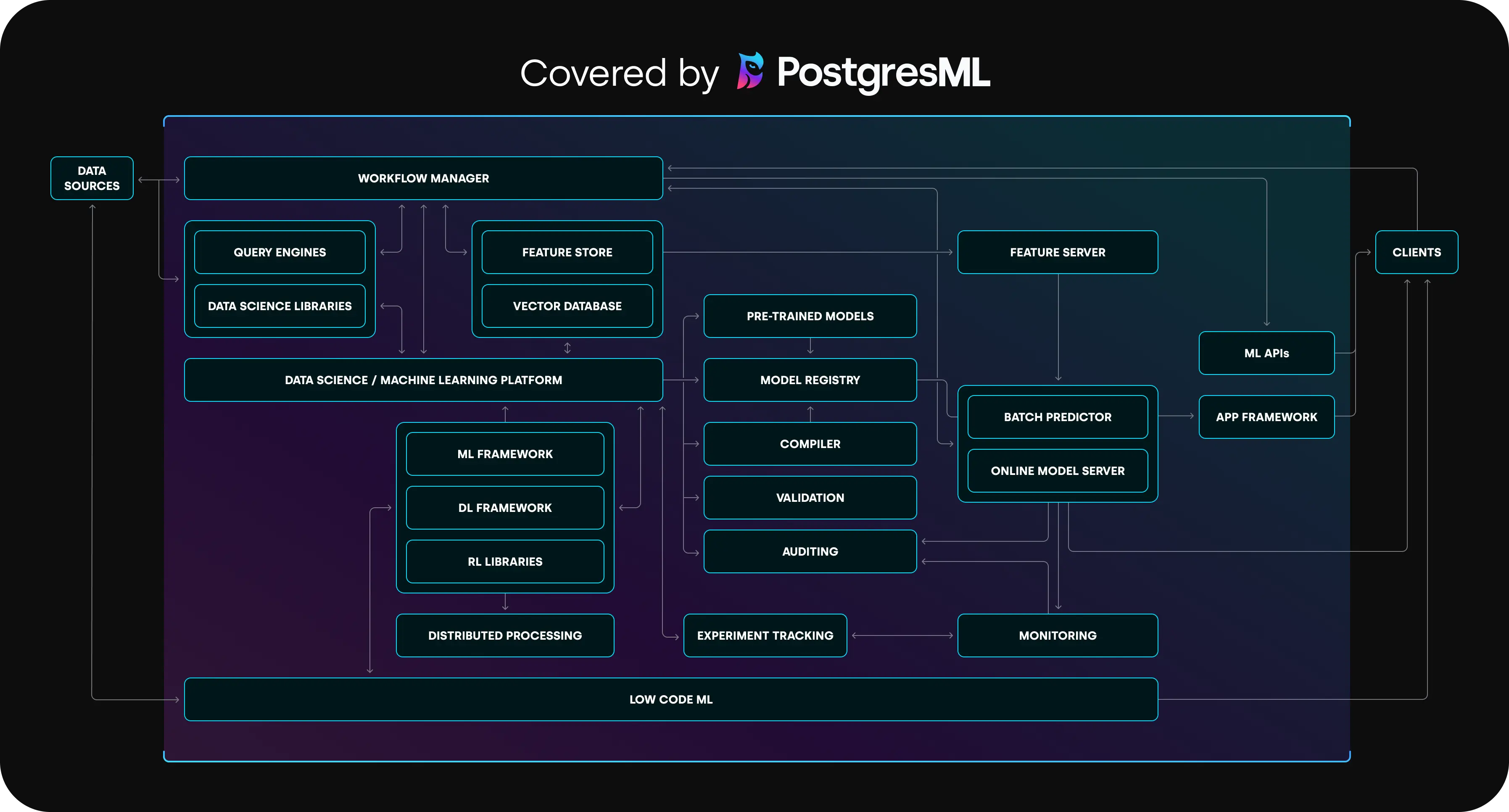
You are running a vector database, an embedding service, LLM APIs, and custom glue code before your app can answer a single user question.
Increasing inefficiency
Separate stacks mean more incidents, slower responses, longer release cycles, and higher spend on inference and search vendors.
Excessive exposure
Your data crosses several vendors and networks, which makes security reviews, retention rules, and compliance harder to prove.
Architecture makes or breaks your app. PostgresML radically simplifies it
PostgresML keeps vectors, models, and application data in one GPU-backed database so you ship RAG and ML features with fewer moving parts.
4x Faster
than  HuggingFace +
HuggingFace +  Pinecone
Pinecone
for a RAG chatbot
10x faster
than  OpenAI for embedding
OpenAI for embedding
generation
Save 42%
On vector database cost
compared to Pinecone
Don't take our word for it.
Run the same Python, JavaScript, or SQL examples against hosted open-source models before you deploy to your own cluster.
New on the blog: HNSW vs IVFFlat indexes for vector search in PostgresML
What makes PostgresML so powerful

Index, filter and re-rank vector embeddings

Generate embeddings

Colocate data and compute
Train, tune and deploy

Get the most of LLMs

Comprehensive platform
Index, filter and re-rank vector embeddings
Generate embeddings
Colocate data and compute
Train, tune and deploy
Get the most of LLMs
Comprehensive platform


Better price for performance
Pay for the models and compute you use, with fewer separate bills for vector search, embeddings, and inference. Many teams replace several tools with one Postgres deployment.
Integrated Libraries
add remove






Models
add removeLanguages
add removeOSS Ecosystem
add remove






Work with what you want
Hear from our community
This is why I’m bullish on @postgresml - devs will always prefer to do things in data stores they already use in production

James yu
@jamesyu
Great article by PostgresML, running @huggingface models INSIDE @PostgreSQL nice tidbit on scalability: "Our example data is based on 5 million DVD reviews from Amazon ... that's more data than fits in a Pinecone Pod at the time of writing"

Paul Copplestone
@kiwicopple
Love the fact that @postgresml can run various algorithms to find the optimum one for model creation

RebataurAI
@rebataur
You can look at PostgresML. Its based on Postgres, not specifically a vector database but they've got a pleasantly full featured eco-system for the whole training process, fetching datasets, huggingface integration, training etc. of course they also have vector related functions

Dushyant (e/acc)
@DevDminGod
If you want to seamlessly integrate machine learning models into your #PostgreSQL database, use PostgresML.

Khuyen Tran
@KhuyenTran16
💯 there's also PostgresML if you wanna get a little more full featured - supports embedding in-database as well as CUBE / pgvector

Martin McFly
@martinmark
Tons of capability in that Postgres extension. It's an important part of the ML Stack at cloud.tembo.io as well.

Adam Hendel
@adamhendel
A game-changer indeed! By integrating ML and AI directly at the database level with @postgresml, we're not just streamlining processes but revolutionizing data handling and insights generation in one fell swoop.

Pranay Suyash
@pranaysuyash
This is why I’m bullish on @postgresml - devs will always prefer to do things in data stores they already use in production
James yu
@jamesyu
Great article by PostgresML, running @huggingface models INSIDE @PostgreSQL nice tidbit on scalability: "Our example data is based on 5 million DVD reviews from Amazon ... that's more data than fits in a Pinecone Pod at the time of writing"
Paul Copplestone
@kiwicopple
Love the fact that @postgresml can run various algorithms to find the optimum one for model creation
RebataurAI
@rebataur
You can look at PostgresML. Its based on Postgres, not specifically a vector database but they've got a pleasantly full featured eco-system for the whole training process, fetching datasets, huggingface integration, training etc. of course they also have vector related functions
Dushyant (e/acc)
@DevDminGod
If you want to seamlessly integrate machine learning models into your #PostgreSQL database, use PostgresML.
Khuyen Tran
@KhuyenTran16
💯 there's also PostgresML if you wanna get a little more full featured - supports embedding in-database as well as CUBE / pgvector
Martin McFly
@martinmark
Tons of capability in that Postgres extension. It's an important part of the ML Stack at cloud.tembo.io as well.
Adam Hendel
@adamhendel
A game-changer indeed! By integrating ML and AI directly at the database level with @postgresml, we're not just streamlining processes but revolutionizing data handling and insights generation in one fell swoop.
Pranay Suyash
@pranaysuyash
Get started
with
$100 in
free credits
 PostgresML
PostgresML
PostgresML 2024 Ⓒ All rights reserved.