Silas Marvin
July 30, 2024
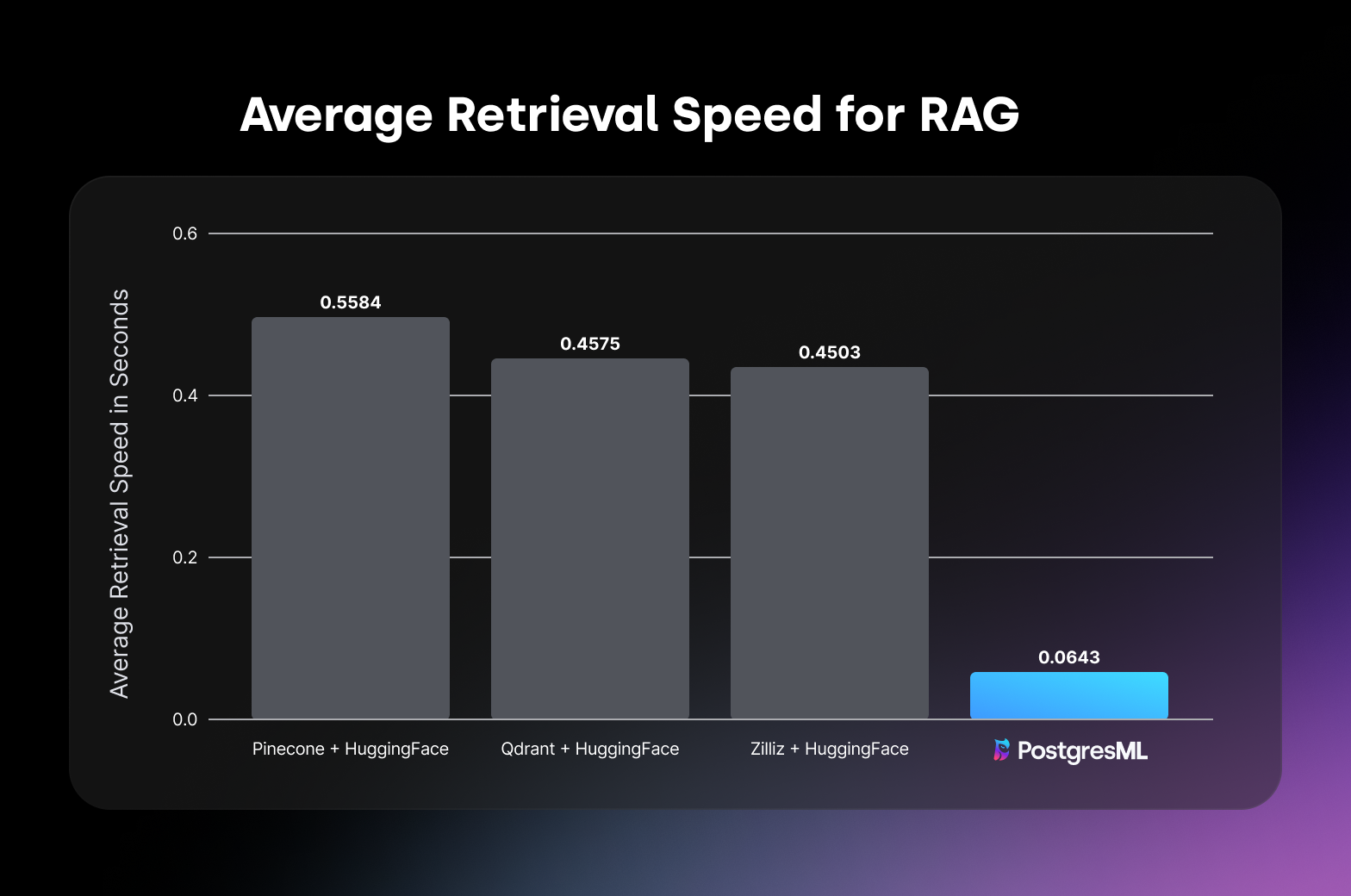
The average retreival speed for RAG in seconds.
We tested a selection of the most popular retrieval systems for RAG:
- Pinecone + HuggingFace
- Qdrant + HuggingFace
- Weaviate + HuggingFace
- Zilliz + HuggingFace
- PostgresML via Korvus
Where are LangChain and LlamaIndex? Both LangChain and LlamIndex serve as orchestration layers. They aren't vector database providers or embedding providers and would only serve to make our Python script shorter (or longer depending on which framework we chose).
Each retrieval system is a vector database + embeddings API pair. To stay consistent, we used HuggingFace as the embeddings API for each vector database, but we could easily switch this for OpenAI or any other popular embeddings API. We first uploaded two documents to each database: one that has a hidden value we will query for later, and one filled with random text. We then tested a small RAG pipeline for each pair that simulated a user asking the question: "What is the hidden value", and getting a response generated by OpenAI.
Pinecone, Qdrant, and Zilliz are only vector databases, so we first embed the query by manually making a request to HuggingFace's API. Then we performed a search over our uploaded documents, and passed the search result as context to OpenAI.
Weaviate is a bit different. They embed and perform text generation for you. Note that we opted to use HuggingFace and OpenAI to stay consistent, which means Weaviate will make API calls to HuggingFace and OpenAI for us, essentially making Weaviate a wrapper around what we did for Pinecone, Qdrant, and Zilliz.
PostgresML is unique as it's not just a vector database, but a full PostgreSQL database with machine learning infrastructure built in. We didn't need to embed the query using an API, we embedded the user's question using SQL in our retrieval query, and passed the result from our search query as context to OpenAI.
We used a small Python script available here to test each RAG system.
This is the direct output from our Python script, which you can run yourself here. These results are averaged over 25 trials.
content_copy
Done Doing RAG Test For: PostgresML
- Average `Time to Embed`: 0.0000
- Average `Time to Search`: 0.0643
- Average `Total Time for Retrieval`: 0.0643
- Average `Time for Chatbot Completion`: 0.6444
- Average `Total Time Taken`: 0.7087
Done Doing RAG Test For: Weaviate
- Average `Time to Embed`: 0.0000
- Average `Time to Search`: 0.0000
- Average `Total Time for Retrieval`: 0.0000
- Average `Time for Chatbot Completion`: 1.2539
- Average `Total Time Taken`: 1.2539
Done Doing RAG Test For: Zilliz
- Average `Time to Embed`: 0.2938
- Average `Time to Search`: 0.1565
- Average `Total Time for Retrieval`: 0.4503
- Average `Time for Chatbot Completion`: 0.5909
- Average `Total Time Taken`: 1.0412
Done Doing RAG Test For: Pinecone
- Average `Time to Embed`: 0.2907
- Average `Time to Search`: 0.2677
- Average `Total Time for Retrieval`: 0.5584
- Average `Time for Chatbot Completion`: 0.5949
- Average `Total Time Taken`: 1.1533
Done Doing RAG Test For: Qdrant
- Average `Time to Embed`: 0.2901
- Average `Time to Search`: 0.1674
- Average `Total Time for Retrieval`: 0.4575
- Average `Time for Chatbot Completion`: 0.6091
- Average `Total Time Taken`: 1.0667
There are 5 metrics listed:
- The
Time for Embedding is the time it takes to do the embedding. Note that it is zero for PostgresML and Weaviate. PostgresML does the embedding in the same query it does the search with, so there is no way to have a separate embedding time. Weaviate does the embedding, search, and generation all at once so it is zero here as well.
- The
Time for Search is the time it takes to perform search over our vector database. In the case of PostgresML, this is the time it takes to embed and do the search in one SQL query. It is zero for Weaviate for reasons mentioned before.
- The
Total Time for Retrieval is the total time it takes to do retrieval. It is the sum of the Time for Embedding and Time for Search.
- The
Time for Chatbot Completion is the time it takes to get the response from OpenAI. In the case of Weaviate, this includes the Time for Retrieval.
- The
Total Time Taken is the total time it takes to perform RAG.
There are a number of ways to interpret these results. First let's sort them by Total Time Taken ASC:
- PostgresML - 0.7087
Total Time Taken
- Zilliz - 1.0412
Total Time Taken
- Qdrant - 1.0667
Total Time Taken
- Pinecone - 1.1533
Total Time Taken
- Weaviate - 1.2539
Total Time Taken
Let's remember that every single RAG system we tested uses OpenAI to perform the Augmented Generation part of RAG. This almost consistently takes about 0.6 seconds, and is part of the Total Time Taken. Because it is roughly constant, let's factor it out and focus on the Total Time for Retrieval (we omit Weaviate as we don't have metrics for that, but if we did factor the constant 0.6 seconds out of the total time it would be sitting at 0.6539):
- PostgresML - 0.0643
Total Time for Retrieval
- Zilliz - 0.4503
Total Time for Retrieval
- Qdrant - 0.4575
Total Time for Retrieval
- Pinecone - 0.5584
Total Time for Retrieval
PostgresML is almost an order of magnitude faster at retrieval than any other system we tested, and it is clear why. Not only is the search itself faster (SQL queries with pgvector using an HNSW index are ridiculously fast), but PostgresML avoids the extra API call to embed the user's query. Because PostgresML can use embedding models in the database, it doesn't need to make an API call to embed.
What does embedding look with SQL? For those new to SQL, it can be as easy as using our Korvus SDK with Python or JavaScript.
The Korvus Python SDK writes all the necessary SQL queries for us and gives us a high level abstraction for creating Collections and Pipelines, and searching and performing RAG.
content_copy
from korvus import Collection, Pipeline
import asyncio
collection = Collection("semantic-search-demo")
pipeline = Pipeline(
"v1",
{
"text": {
"splitter": {"model": "recursive_character"},
"semantic_search": {
"model": "mixedbread-ai/mxbai-embed-large-v1",
},
},
},
)
async def main():
await collection.add_pipeline(pipeline)
documents = [
{
"id": "1",
"text": "The hidden value is 1000",
},
{
"id": "2",
"text": "Korvus is incredibly fast and easy to use.",
},
]
await collection.upsert_documents(documents)
results = await collection.vector_search(
{
"query": {
"fields": {
"text": {
"query": "What is the hidden value",
"parameters": {
"prompt": "Represent this sentence for searching relevant passages: ",
},
},
},
},
"document": {"keys": ["id"]},
"limit": 1,
},
pipeline,
)
print(results)
asyncio.run(main())
content_copy
[{'chunk': 'The hidden value is 1000', 'document': {'id': '1'}, 'rerank_score': None, 'score': 0.7257088435203306}]
content_copy
SELECT pgml.embed(
transformer => 'mixedbread-ai/mxbai-embed-large-v1',
text => 'What is the hidden value'
) AS "embedding";
Using the pgml.embed function we can build out whole retrieval pipelines
content_copy
-- Create a documents table
CREATE TABLE documents (
id serial PRIMARY KEY,
text text NOT NULL,
embedding vector (384) -- Uses the vector data type from pgvector with dimension 384
);
-- Creates our HNSW index for super fast retreival
CREATE INDEX documents_vector_idx ON documents USING hnsw (embedding vector_cosine_ops);
-- Insert a few documents
INSERT INTO documents (text, embedding)
VALUES ('The hidden value is 1000', (
SELECT pgml.embed (transformer => 'mixedbread-ai/mxbai-embed-large-v1', text => 'The hidden value is 1000'))),
('This is just some random text',
(
SELECT pgml.embed (transformer => 'mixedbread-ai/mxbai-embed-large-v1', text => 'This is just some random text')));
-- Do a query over it
WITH "query_embedding" AS (
SELECT
pgml.embed (transformer => 'mixedbread-ai/mxbai-embed-large-v1', text => 'What is the hidden value', '{"prompt": "Represent this sentence for searching relevant passages: "}') AS "embedding"
)
SELECT
"text",
1 - (embedding <=> (
SELECT embedding
FROM "query_embedding")::vector) AS score
FROM
documents
ORDER BY
embedding <=> (
SELECT embedding
FROM "query_embedding")::vector ASC
LIMIT 1;
content_copy
text | score
--------------------------+--------------------
The hidden value is 1000 | 0.9132997445285489
Give it a spin, and let us know what you think. We're always here to geek out about databases and machine learning, so don't hesitate to reach out if you have any questions or ideas. We welcome you to:
Here's to simpler architectures and more powerful queries!