Making Postgres 30 Percent Faster in Production
Anyone who runs Postgres at scale knows that performance comes with trade offs. The typical playbook is to place a pooler like PgBouncer in front of your database and turn on transaction mode. This makes multiple clients reuse the same server connection, which allows thousands of clients to connect to your database without causing a fork bomb.
Unfortunately, this comes with a trade off. Since multiple clients use the same server, they couldn't take advantage of prepared statements. Prepared statements are a way for Postgres to cache a query plan and execute it multiple times with different parameters. If you have never tried this before, you can run pgbench against your local DB and you'll see that --protocol prepared outperforms simple and extended by at least 30 percent. Giving up this feature has been a given for production deployments for as long as I can remember, but not anymore.
PgCat Prepared Statements
Since #474, PgCat supports prepared statements in session and transaction mode. Our initial benchmarks show 30% increase over extended protocol (--protocol extended) and 15% against simple protocol (--simple). Most (all?) web frameworks use at least the extended protocol, so we are looking at a 30% performance increase across the board for everyone who writes web apps and uses Postgres in production, by just switching to named prepared statements.
In Rails apps, it's as simple as setting prepared_statements: true.
This is not only a performance benefit, but also a usability improvement for client libraries that have to use prepared statements, like the popular Rust crate SQLx. Until now, the typical recommendation was to just not use a pooler.
Benchmark

The benchmark was conducted using pgbench with 1, 10, 100 and 1000 clients sending millions of queries to PgCat, which itself was running on a different EC2 machine alongside the database. This is a simple setup often used in production. Another configuration sees a pooler use its own machine, which of course increases latency but improves on availability. The clients were on another EC2 machine to simulate the latency experienced in typical web apps deployed in Kubernetes, ECS, EC2 and others.
Benchmark ran in transaction mode. Session mode is faster with fewer clients, but does not scale in production with more than a few hundred clients. Only SELECT statements (-S option) were used, since the typical pgbench benchmark uses a similar number of writes to reads, which is an atypical production workload. Most apps read 90% of the time, and write 10% of the time. Reads are where prepared statements truly shine.
Implementation
PgCat implements an internal cache & mapping between clients' prepared statements and servers that may or may not have them. If a server has the prepared statement, PgCat just forwards the Bind (F), Execute (F) and Describe (F) messages. If the server doesn't have the prepared statement, PgCat fetches it from the client cache & prepares it using the Parse (F) message. You can refer to Postgres docs for a more detailed explanation of how the extended protocol works.
An important feature of PgCat's implementation is that all prepared statements are renamed and assigned globally unique names. This means that clients that don't randomize their prepared statement names and expect it to be gone after they disconnect from the "Postgres server", work as expected (I put "Postgres server" in quotes because they are actually talking to a proxy that pretends to be a Postgres database). Typical error when using such clients with PgBouncer is prepared statement "sqlx_s_2" already exists, which is pretty confusing when you see it for the first time.
Metrics
We've added two new metrics to the admin database: prepare_cache_hit and prepare_cache_miss. Prepare cache hits indicate that the prepared statement requested by the client already exists on the server. That's good because PgCat can just rewrite the messages and send them to the server immediately. Prepare cache misses indicate that PgCat had to issue a prepared statement call to the server, which requires additional time and decreases throughput. In the ideal scenario, the cache hits outnumber the cache misses by an order of magnitude. If they are the same or worse, the prepared statements are not being used correctly by the clients.
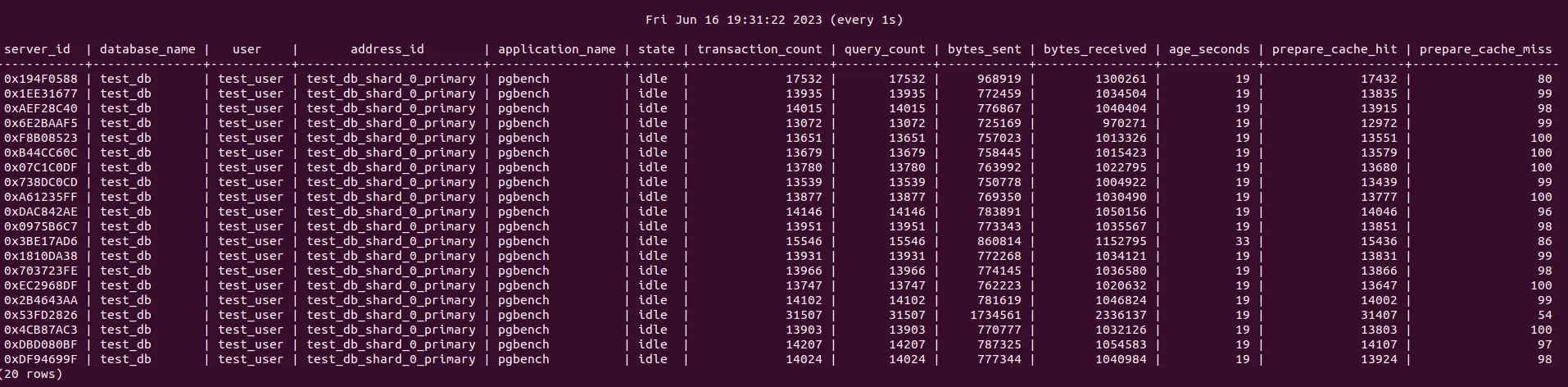
Our benchmark had a 99.99% cache hit ratio, which is really good, but in production this number is likely to be lower. You can monitor your cache hit/miss ratios through the admin database by querying it with SHOW SERVERS.
Roadmap
Our implementation is pretty simple and we are already seeing massive improvements, but we can still do better. A Parse (F) made prepared statement works, but if one prepares their statements using PREPARE explicitly, PgCat will ignore it and that query isn't likely to work outside of session mode.
Another issue is explicit DEALLOCATE and DISCARD calls. PgCat doesn't detect them currently, and a client can potentially bust the server prepared statement cache without PgCat knowing about it. It's an easy enough fix to intercept and act on that query accordingly, but we haven't built that yet.
Testing with pgbench is an artificial benchmark, which is good and bad. It's good because, other things being equal, we can demonstrate that one implementation & configuration of the database/pooler cluster is superior to another. It's bad because in the real world, the results can differ. We are looking for users who would be willing to test our implementation against their production traffic and tell us how we did. This feature is optional and can be enabled & disabled dynamically, without restarting PgCat, with prepared_statements = true in pgcat.toml.