MindsDB vs PostgresML
Introduction
There are a many ways to do machine learning with data in a SQL database. In this article, we'll compare 2 projects that both aim to provide a SQL interface to machine learning algorithms and the data they require: MindsDB and PostgresML. We'll look at how they work, what they can do, and how they compare to each other. The TLDR is that PostgresML is more opinionated, more scalable, more capable and several times faster than MindsDB. On the other hand, MindsDB is 5 times more mature than PostgresML according to age and GitHub Stars. What are the important factors?
We're occasionally asked what the difference is between PostgresML and MindsDB. We'd like to answer that question at length, and let you decide if the reasoning is fair.
At a glance
Both projects are Open Source, although PostgresML allows for more permissive use with the MIT license, compared to the GPL-3.0 license used by MindsDB. PostgresML is also a significantly newer project, with the first commit in 2022, compared to MindsDB which has been around since 2017, but one of the first hints at the real differences between the two projects is the choice of programming languages. MindsDB is implemented in Python, while PostgresML is implemented with Rust. I say in Python, because it's a language with a runtime, and with Rust, because it's a language with a compiler that does not require a Runtime. We'll see how this difference in implementation languages leads to different outcomes.
| MindsDB | PostgresML | |
|---|---|---|
| Age | 5 years | 1 year |
| License | GPL-3.0 | MIT |
| Language | Python | Rust |
Algorithms
Both Projects integrate several dozen machine learning algorithms, including the latest LLMs from Hugging Face.
| MindsDB | PostgresML | |
|---|---|---|
| Classification | ✅ | ✅ |
| Regression | ✅ | ✅ |
| Time Series | ✅ | ✅ |
| LLM Support | ✅ | ✅ |
| Embeddings | - | ✅ |
| Vector Support | - | ✅ |
| Full Text Search | - | ✅ |
| Geospatial Search | - | ✅ |
Both MindsDB and PostgresML support many classical machine learning algorithms to do classification and regression. They are both able to load the latest LLMs some models from Hugging Face, supported by underlying implementations in libtorch. I had to cross that out after exploring all the caveats in the MindsDB implementations. PostgresML supports the models released immediately as long as underlying dependencies are met. MindsDB has to release an update to support any new models, and their current model support is extremely limited. New algorithms, tasks, and models are constantly released, so it's worth checking the documentation for the latest list.
Another difference is that PostgresML also supports embedding models, and closely integrates them with vector search inside the database, which is well beyond the scope of MindsDB, since it's not a database at all. PostgresML has direct access to all the functionality provided by other Postgres extensions, like vector indexes from pgvector to perform efficient KNN & ANN vector recall, or PostGIS for geospatial information as well as built in full text search. Multiple algorithms and extensions can be combined in compound queries to build state-of-the-art systems, like search and recommendations or fraud detection that generate an end to end result with a single query, something that might take a dozen different machine learning models and microservices in a more traditional architecture.
Architecture
The architectural implementations for these projects is significantly different. PostgresML takes a data centric approach with Postgres as the provider for both storage and compute. To provide horizontal scalability for inference, the PostgresML team has also created PgCat to distribute workloads across many Postgres databases. On the other hand, MindsDB takes a service oriented approach that connects to various databases over the network.
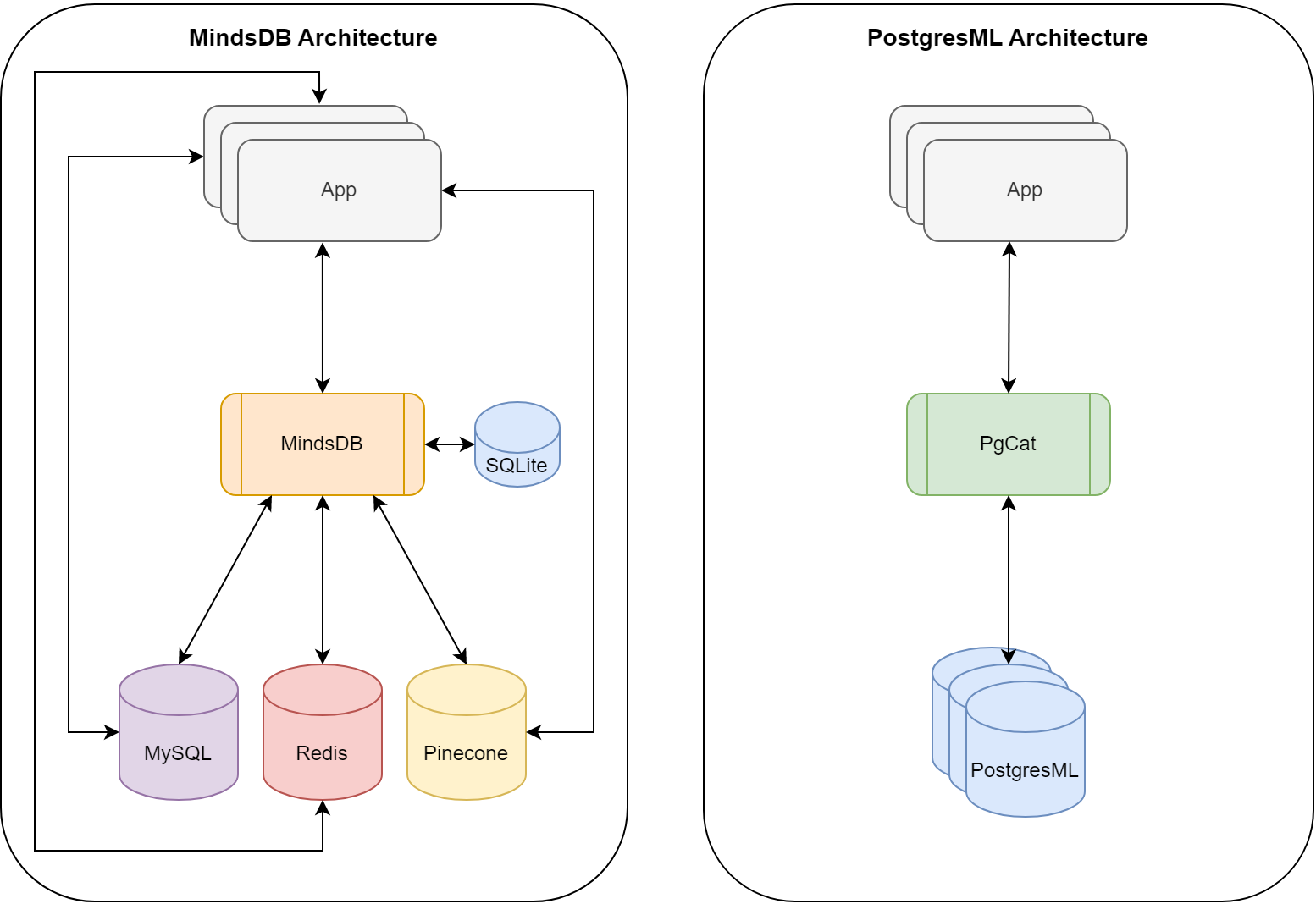
| MindsDB | PostgresML | |
|---|---|---|
| Data Access | Over the wire | In process |
| Multi Process | ✅ | ✅ |
| Database | - | ✅ |
| Replication | - | ✅ |
| Sharding | - | ✅ |
| Cloud Hosting | ✅ | ✅ |
| On Premise | ✅ | ✅ |
| Web UI | ✅ | ✅ |
The difference in architecture leads to different tradeoffs and challenges. There are already hundreds of ways to get data into and out of a Postgres database, from just about every other service, language and platform that makes PostgresML highly compatible with other application workflows. On the other hand, the MindsDB Python service accepts connections from specifically supported clients like psql and provides a pseudo-SQL interface to the functionality. The service will parse incoming MindsDB commands that look similar to SQL (but are not), for tasks like configuring database connections, or doing actual machine learning. These commands typically have what looks like a sub-select, that will actually fetch data over the wire from configured databases for Machine Learning training and inference.
MindsDB is actually a pretty standard Python microservice based architecture that separates data from compute over the wire, just with an SQL like API, instead of gRPC or REST. MindsDB isn't actually a DB at all, but rather an ML service with adapters for just about every database that Python can connect to.
On the other hand, PostgresML runs ML algorithms inside the database itself. It shares memory with the database, and can access data directly, using pointers to avoid the serialization and networking overhead that frequently dominates data hungry machine learning applications. Rust is an important language choice for PostgresML because its memory safety simplifies the effort required to achieve stability along with performance in a large and complex memory space. The "tradeoff", is that it requires a Postgres database to actually host the data it operates on.
In addition to the extension, PostgresML relies on PgCat to scale Postgres clusters horizontally using both sharding and replication strategies to provide both scalable compute and storage. Scaling a low latency and high availability feature store is often the most difficult operational challenge for Machine Learning applications. That's the primary driver of PostgresML's architectural choices. MindsDB leaves those issues as an exercise for the adopter, while also introducing a new single service bottleneck for ML compute implemented in Python.
Benchmarks
If you missed our previous article benchmarking PostgresML vs Python Microservices, spoiler alert, PostgresML is between 8-40x faster than Python microservice architectures that do the same thing, even if they use "specialized" in memory databases like Redis. The network transit cost as well as data serialization is a major cost for data hungry machine learning algorithms. Since MindsDB doesn't actually provide a DB, we'll create a synthetic benchmark that doesn't use stored data in a database (even though that's the whole point of SQL ML, right?). This will negate the network serialization and transit costs a MindsDB service would typically occur, and highlight the performance differences between Python and Rust implementations.
PostgresML
We'll connect to our Postgres server running locally:
psql postgres://postgres:password@127.0.0.1:5432
For both implementations, we can just pass in our data as part of the query for an apples to apples performance comparison. PostgresML adds the pgml.transform function, that takes an array of inputs to transform, given a task and model, without any setup beyond installing the extension. Let's see how long it takes to run a sentiment analysis model on a single sentence:
SELECT pgml.transform(
inputs => ARRAY[
'I am so excited to benchmark deep learning models in SQL. I can not wait to see the results!'
],
task => '{
"task": "text-classification",
"model": "cardiffnlp/twitter-roberta-base-sentiment"
}'::JSONB
);
| positivity |
|---|
| [{"label": "LABEL_2", "score": 0.990081250667572}] |
The first time transform is run with a particular model name, it will download that pretrained transformer from HuggingFace, and load it into RAM, or VRAM if a GPU is available. In this case, that took about 5 seconds, but let's see how fast it is now that the model is cached.
SELECT pgml.transform(
inputs => ARRAY[
'I don''t really know if 5 seconds is fast or slow for deep learning. How much time is spent downloading vs running the model?'
],
task => '{
"task": "text-classification",
"model": "cardiffnlp/twitter-roberta-base-sentiment"
}'::JSONB
);
| transform |
|---|
| [{"label": "LABEL_1", "score": 0.49658918380737305}] |
45ms is below the level of human perception, so we could use a deep learning model like this to build an interactive application that feels instantaneous to our users. It's worth noting that PostgresML will automatically use a GPU if it's available. This benchmark machine includes an NVIDIA RTX 3090. We can also check the speed on CPU only, by setting the device argument to cpu:
SELECT pgml.transform(
inputs => ARRAY[
'Are GPUs really worth it? Sometimes they are more expensive than the rest of the computer combined.'
],
task => '{
"task": "text-classification",
"model": "cardiffnlp/twitter-roberta-base-sentiment",
"device": "cpu"
}'::JSONB
);
| transform |
|---|
| [{"label": "LABEL_0", "score": 0.7333963513374329}] |
The GPU is able to run this model about 4x faster than the i9-13900K with 24 cores.
Model Outputs
You might have noticed that the inputs the model was analyzing got less positive over time, and the model moved from LABEL_2 to LABEL_1 to LABEL_0. Some models use more descriptive outputs, but in this case I had to look at the README to see what the labels represent.
Labels:
- 0 -> Negative
- 1 -> Neutral
- 2 -> Positive
It looks like this model did correctly pick up on the decreasing enthusiasm in the text, so not only is it relatively fast on a GPU, it's usefully accurate. Another thing to consider when it comes to model quality is that this model was trained on tweets, and these inputs were chosen to be about as long and complex as a tweet. It's not always clear how well a model will generalize to novel looking inputs, so it's always important to do a little reading about a model when you're looking for ways to test and improve the quality of it's output.
MindsDB
MindsDB requires a bit more setup than just the database, but I'm running it on the same machine with the latest version. I'll also use the same model, so we can compare apples to apples.
python -m mindsdb --api postgres
Then we can connect to this Python service with our Postgres client:
psql postgres://mindsdb:123@127.0.0.1:55432
And turn timing on to see how long it takes to run the same query:
\timing on
And now we can issue some MindsDB pseudo sql:
CREATE MODEL mindsdb.sentiment_classifier
PREDICT sentiment
USING
engine = 'huggingface',
task = 'text-classification',
model_name = 'cardiffnlp/twitter-roberta-base-sentiment',
input_column = 'text',
labels = ['negativ', 'neutral', 'positive'];
This kicked off a background job in the Python service to download the model and set it up, which took about 4 seconds judging from the logs, but I don't have an exact time for exactly when the model became "status: complete" and was ready to handle queries.
Now we can write a query that will make a prediction similar to PostgresML, using the same Huggingface model.
SELECT *
FROM mindsdb.sentiment_classifier
WHERE text = 'I am so excited to benchmark deep learning models in SQL. I can not wait to see the results!'
| sentiment | sentiment_explain | text |
|---|---|---|
| positive | {"positive": 0.990081250667572, "neutral": 0.008058485575020313, "negativ": 0.0018602772615849972} | I am so excited to benchmark deep learning models in SQL. I can not wait to see the results! |
Since we've provided the MindsDB model with more human-readable labels, they're reusing those (including the negativ typo), and returning all three scores along with the input by default. However, this seems to be a bit slower than anything we've seen so far. Let's try to speed it up by only returning the label without the full sentiment_explain.
SELECT sentiment
FROM mindsdb.sentiment_classifier
WHERE text = 'I am so excited to benchmark deep learning models in SQL. I can not wait to see the results!'
| sentiment |
|---|
| positive |
It's not the sentiment_explain that's slowing it down. I spent several hours of debugging, and learned a lot more about the internal Python service architecture. I've confirmed that even though inside the Python service, torch.cuda.is_available() returns True when the service starts, I never see a Python process use the GPU with nvidia-smi. MindsDB also claims to run on GPU, but I haven't been able to find any documentation, or indication in the code why it doesn't "just work". I'm stumped on this front, but I think it's fair to assume this is a pure CPU benchmark.
The other thing I learned trying to get this working is that MindsDB isn't just a single Python process. Python famously has a GIL that will impair parallelism, so the MindsDB team has cleverly built a service that can run multiple Python processes in parallel. This is great for scaling out, but it means that our query is serialized to JSON and sent to a worker, and then the worker actually runs the model and sends the results back to the parent, again as JSON, which as far as I can tell is where the 5x slow-down is happening.
Results
PostgresML is the clear winner in terms of performance. It seems to me that it currently also support more models with a looser function API than the pseudo SQL required to create a MindsDB model. You'll notice the output structure for models on HuggingFace can very widely. I tried several not listed in the MindsDB documentation, but received errors on creation. PostgresML just returns the models output without restructuring, so it's able to handle more discrepancies, although that does leave it up to the end user to sort out how to use models.
| task | model | MindsDB | PostgresML CPU | PostgresML GPU |
|---|---|---|---|---|
| text-classification | cardiffnlp/twitter-roberta-base-sentiment | 741 | 165 | 45 |
| translation_en_to_es | t5-base | 1573 | 1148 | 294 |
| summarization | sshleifer/distilbart-cnn-12-6 | 4289 | 3450 | 479 |
There is a general trend, the larger and slower the model is, the more work is spent inside libtorch, the less the performance of the rest matters, but for interactive models and use cases there is a significant difference. We've tried to cover the most generous use case we could between these two. If we were to compare XGBoost or other classical algorithms, that can have sub millisecond prediction times in PostgresML, the 20ms Python service overhead of MindsDB just to parse the incoming query would be hundreds of times slower.
Clouds
Setting these services up is a bit of work, even for someone heavily involved in the day-to-day machine learning mayhem. Managing machine learning services and databases at scale requires a significant investment over time. Both services are available in the cloud, so let's see how they compare on that front as well.
MindsDB is available on the AWS marketplace on top of your own hardware instances. You can scale it out and configure your data sources through their Web UI, very similar to the local installation, but you'll also need to figure out your data sources and how to scale them for machine learning workloads. Good luck!
PostgresML is available as a fully managed database service, that includes the storage, backups, metrics, and scalability through PgCat that large ML deployments need. End-to-end machine learning is rarely just about running the models, and often more about scaling the data pipelines and managing the data infrastructure around them, so in this case PostgresML also provides a large service advantage, whereas with MindsDB, you'll still need to figure out your cloud data storage solution independently.