PostgresML is 8-40x faster than Python HTTP microservices
Machine learning architectures can be some of the most complex, expensive and difficult arenas in modern systems. The number of technologies and the amount of required hardware compete for tightening headcount, hosting, and latency budgets. Unfortunately, the trend in the industry is only getting worse along these lines, with increased usage of state-of-the-art architectures that center around data warehouses, microservices and NoSQL databases.
PostgresML is a simpler alternative to that ever-growing complexity. In this post, we explore some additional performance benefits of a more elegant architecture and discover that PostgresML outperforms traditional Python microservices by a factor of 8 in local tests and by a factor of 40 on AWS EC2.
Candidate architectures
To consider Python microservices with every possible advantage, our first benchmark is run with Python and Redis located on the same machine. Our goal is to avoid any additional network latency, which puts it on a more even footing with PostgresML. Our second test takes place on AWS EC2, with Redis and Gunicorn separated by a network; this benchmark proves to be relatively devastating.
The full source code for both benchmarks is available on Github.
PostgresML
PostgresML architecture is composed of:
- A PostgreSQL server with PostgresML v2.0
- pgbench SQL client
Python
Python architecture is composed of:
- A Flask/Gunicorn server accepting and returning JSON
- CSV file with the training data
- Redis feature store with the inference dataset, serialized with JSON
- ab HTTP client
ML
Both architectures host the same XGBoost model, running predictions against the same dataset. See Methodology for more details.
Results
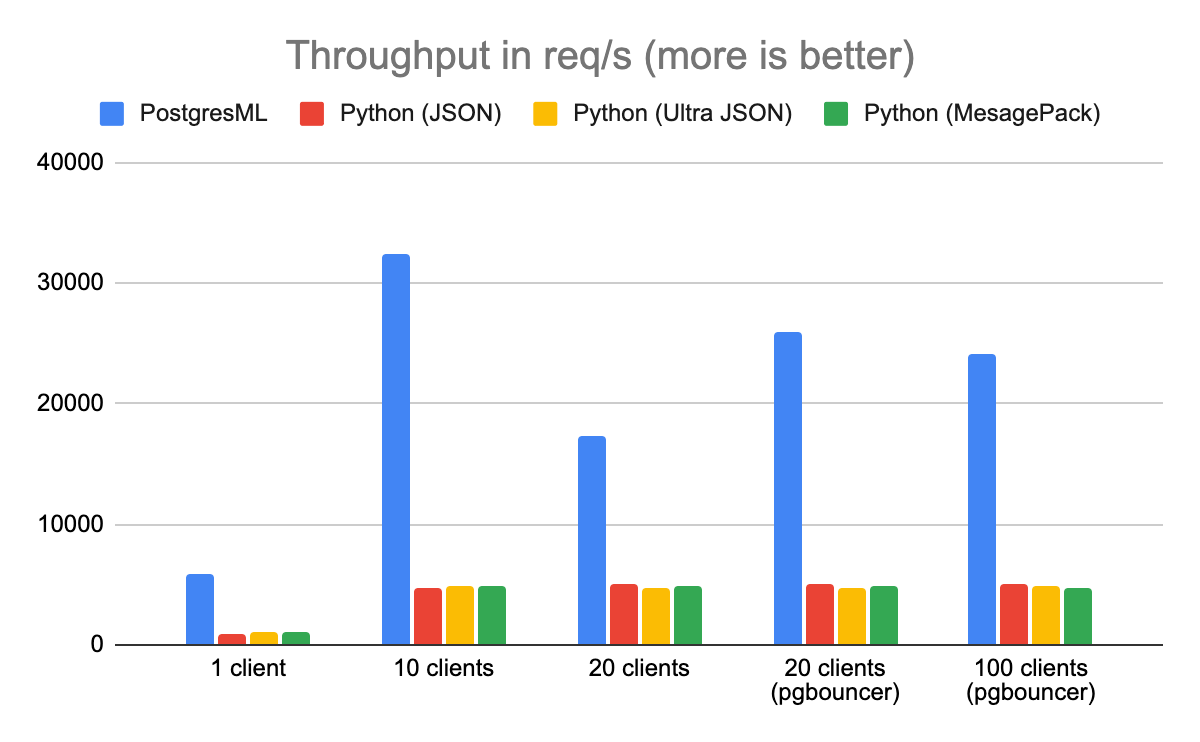
Throughput
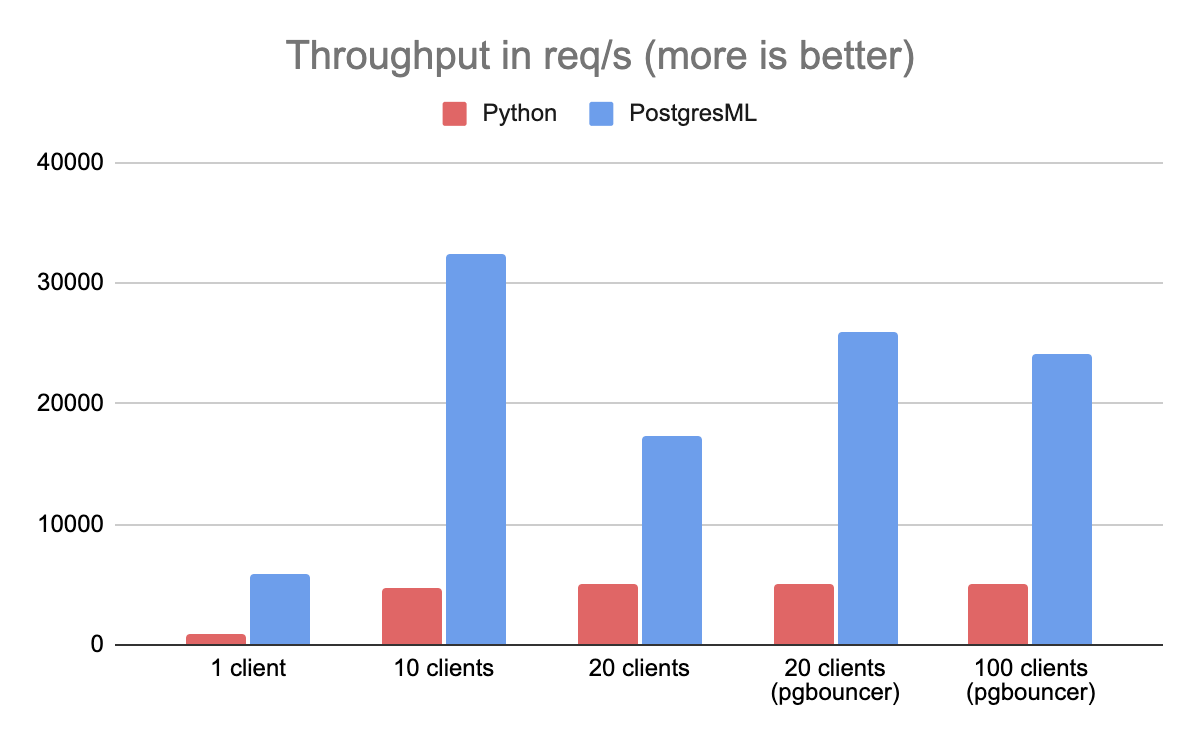
Throughput is defined as the number of XGBoost predictions the architecture can serve per second. In this benchmark, PostgresML outperformed Python and Redis, running on the same machine, by a factor of 8.
In Python, most of the bottleneck comes from having to fetch and deserialize Redis data. Since the features are externally stored, they need to be passed through Python and into XGBoost. XGBoost itself is written in C++, and it's Python library only provides a convenient interface. The prediction coming out of XGBoost has to go through Python again, serialized as JSON, and sent via HTTP to the client.
This is pretty much the bare minimum amount of work you can do for an inference microservice.
PostgresML, on the other hand, collocates data and compute. It fetches data from a Postgres table, which already comes in a standard floating point format, and the Rust inference layer forwards it to XGBoost via a pointer.
An interesting thing happened when the benchmark hit 20 clients: PostgresML throughput starts to quickly decrease. This may be surprising to some, but to Postgres enthusiasts it's a known issue: Postgres isn't very good at handling more concurrent active connections than CPU threads. To mitigate this, we introduced PgBouncer (a Postgres proxy and pooler) in front of the database, and the throughput increased back up, and continued to hold as we went to 100 clients.
It's worth noting that the benchmarking machine had only 16 available CPU threads (8 cores). If more cores were available, the bottleneck would only occur with more clients. The general recommendation for Postgres servers it to open around 2 connections per available CPU core, although newer versions of PostgreSQL have been incrementally chipping away at this limitation.
Why throughput is important
Throughput allows you to do more with less. If you're able to serve 30,000 queries per second using a single machine, but only using 1,000 today, you're unlikely to need an upgrade anytime soon. On the other hand, if the system can only serve 5,000 requests, an expensive and possibly stressful upgrade is in your near future.
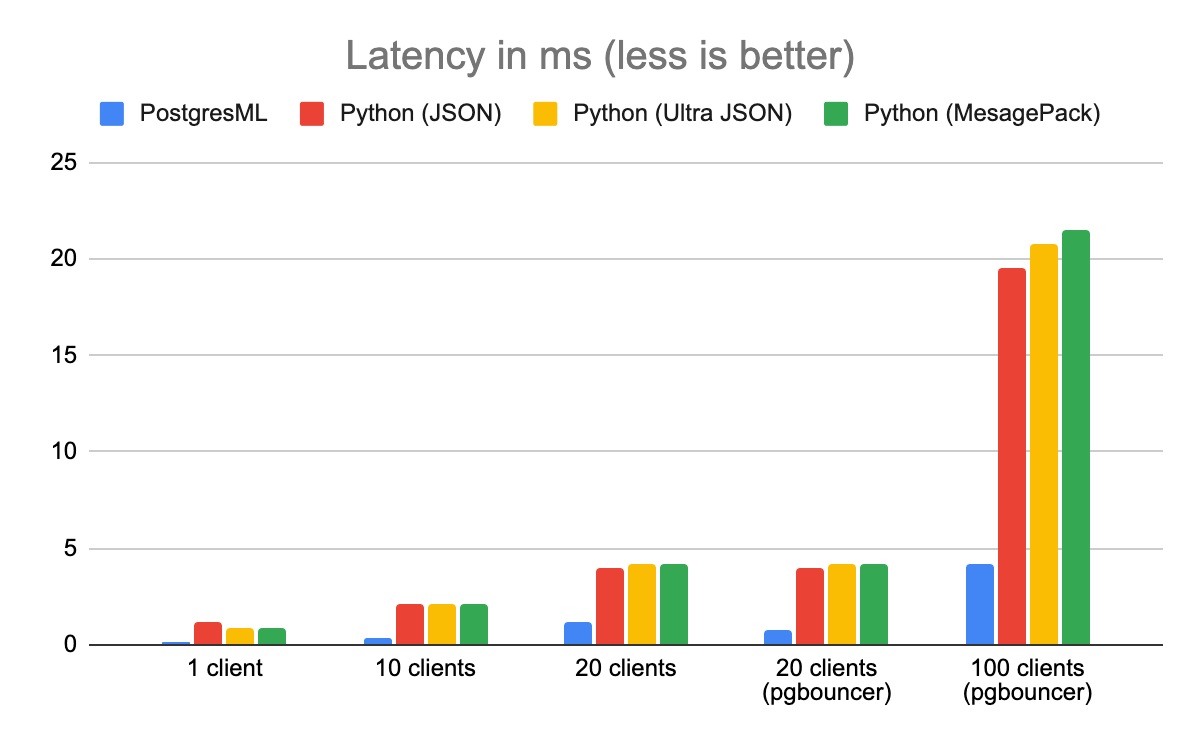
Latency
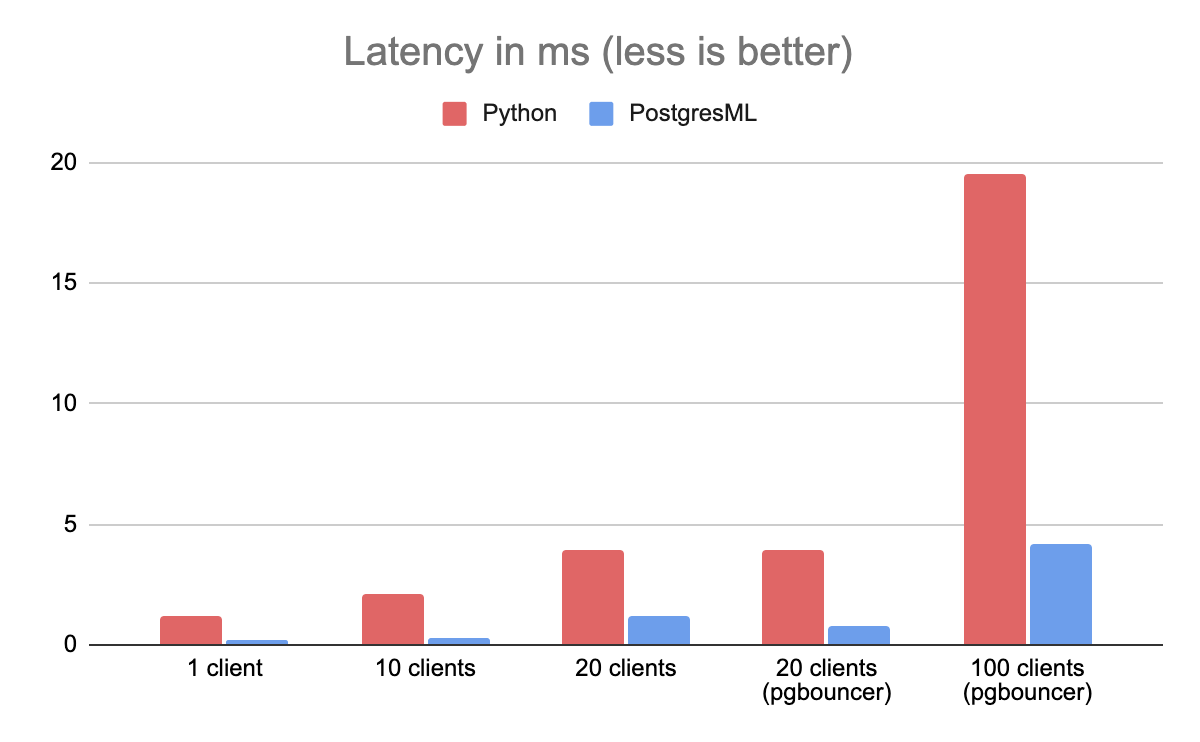
Latency is defined as the time it takes to return a single XGBoost prediction. Since most systems have limited resources, throughput directly impacts latency (and vice versa). If there are many active requests, clients waiting in the queue take longer to be serviced, and overall system latency increases.
In this benchmark, PostgresML outperformed Python by a factor of 8 as well. You'll note the same issue happens at 20 clients, and the same mitigation using PgBouncer reduces its impact. Meanwhile, Python's latency continues to increase substantially.
Latency is a good metric to use when describing the performance of an architecture. In other words, if I were to use this service, I would get a prediction back in at most this long, irrespective of how many other clients are using it.
Why latency is important
Latency is important in machine learning services because they are often running as an addition to the main application, and sometimes have to be accessed multiple times during the same HTTP request.
Let's take the example of an e-commerce website. A typical storefront wants to show many personalization models concurrently. Examples of such models could include "buy it again" recommendations for recurring purchases (binary classification), or "popular items in your area" (geographic clustering of purchase histories) or "customers like you bought this item" (nearest neighbour model).
All of these models are important because they have been proven, over time, to be very successful at driving purchases. If inference latency is high, the models start to compete for very expensive real estate, front page and checkout, and the business has to drop some of them or, more likely, suffer from slow page loads. Nobody likes a slow app when they are trying to order groceries or dinner.
Memory utilization
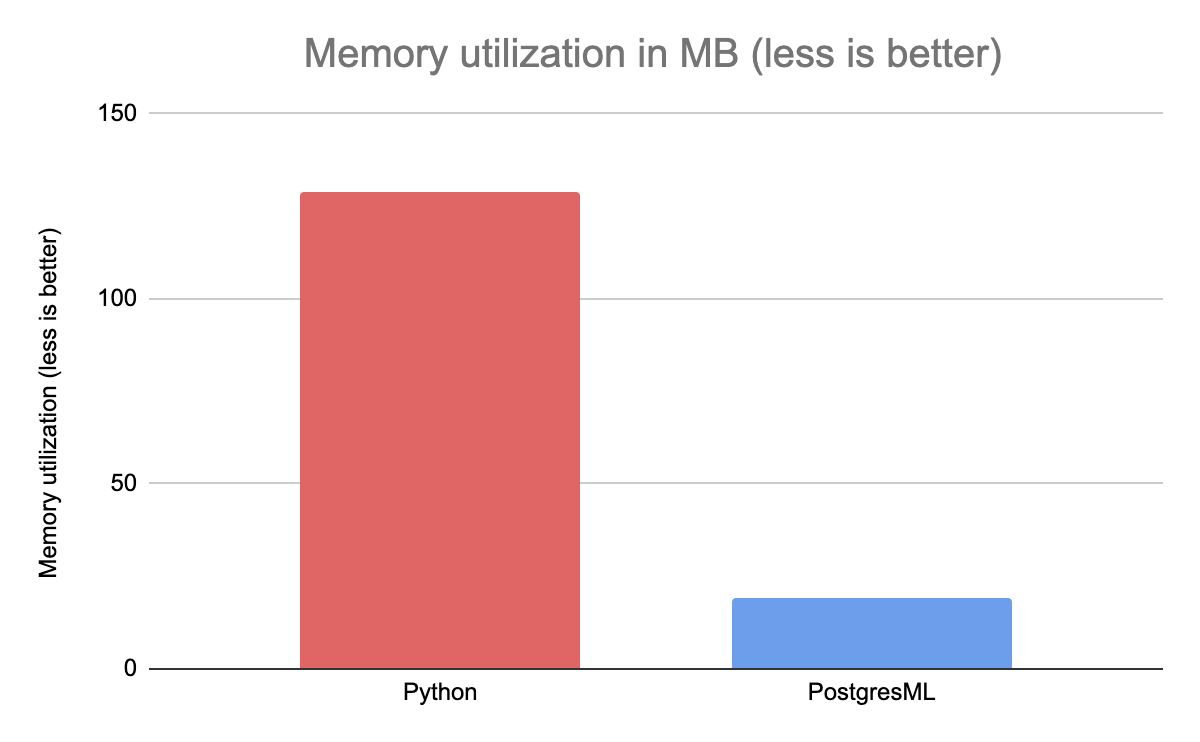
Python is known for using more memory than more optimized languages and, in this case, it uses 7 times more than PostgresML.
PostgresML is a Postgres extension, and it shares RAM with the database server. Postgres is very efficient at fetching and allocating only the memory it needs: it reuses shared_buffers and OS page cache to store rows for inference, and requires very little to no memory allocation to serve queries.
Meanwhile, Python must allocate memory for each feature it receives from Redis and for each HTTP response it returns. This benchmark did not measure Redis memory utilization, which is an additional and often substantial cost of running traditional machine learning microservices.
Training
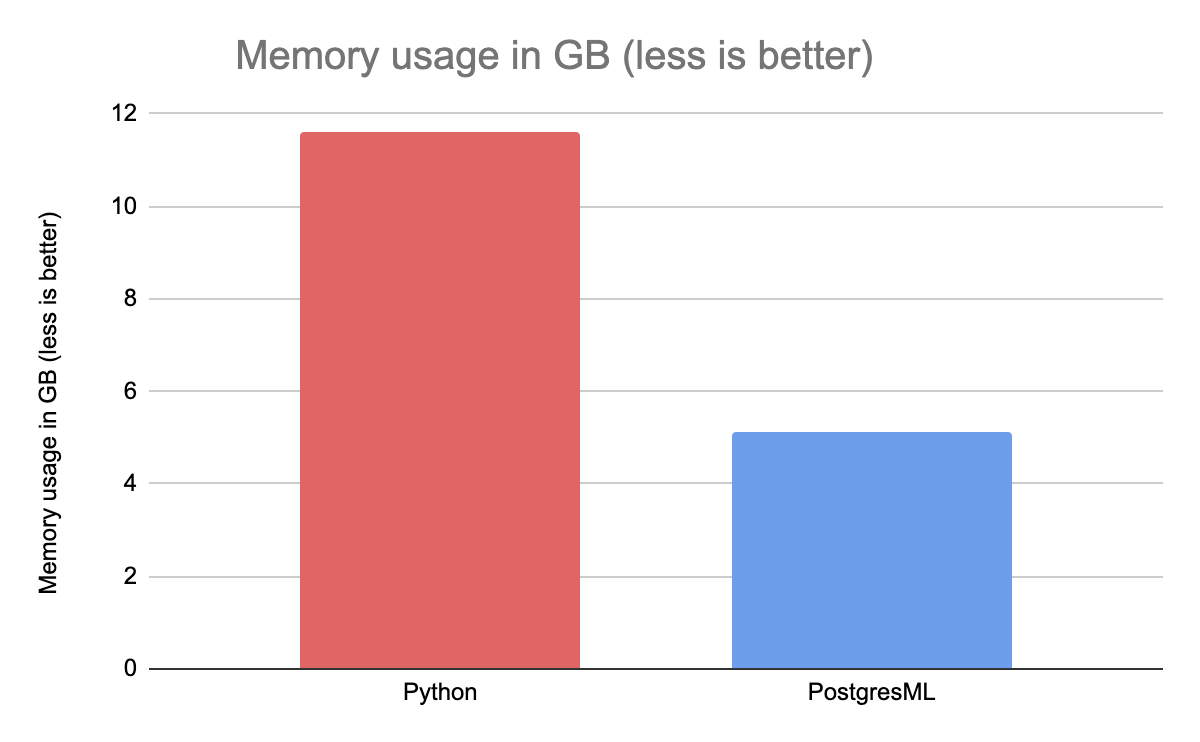
Since Python often uses Pandas to load and preprocess data, it is notably more memory hungry. Before even passing the data into XGBoost, we were already at 8GB RSS (resident set size); during actual fitting, memory utilization went to almost 12GB. This test is another best case scenario for Python, since the data has already been preprocessed, and was merely passed on to the algorithm.
Meanwhile, PostresML enjoys sharing RAM with the Postgres server and only allocates the memory needed by XGBoost. The dataset size was significant, but we managed to train the same model using only 5GB of RAM. PostgresML therefore allows training models on datasets at least twice as large as Python, all the while using identical hardware.
Why memory utilization is important
This is another example of doing more with less. Most machine learning algorithms, outside of FAANG and research universities, require the dataset to fit into the memory of a single machine. Distributed training is not where we want it to be, and there is still so much value to be extracted from simple linear regressions.
Using less RAM allows to train larger and better models on larger and more complete datasets. If you happen to suffer from large machine learning compute bills, using less RAM can be a pleasant surprise at the end of your fiscal year.
What about UltraJSON/MessagePack/Serializer X?
We spent a lot of time talking about serialization, so it makes sense to look at prior work in that field.
JSON is the most user-friendly format, but it's certainly not the fastest. MessagePack and Ultra JSON, for example, are sometimes faster and more efficient at reading and storing binary information. So, would using them in this benchmark be better, instead of Python's built-in json module?
The answer is: not really.
Time to (de)serialize is important, but ultimately needing (de)serialization in the first place is the bottleneck. Taking data out of a remote system (e.g. a feature store like Redis), sending it over a network socket, parsing it into a Python object (which requires memory allocation), only to convert it again to a binary type for XGBoost, is causing unnecessary delays in the system.
PostgresML does one in-memory copy of features from Postgres. No network, no (de)serialization, no unnecessary latency.
What about the real world?
Testing over localhost is convenient, but it's not the most realistic benchmark. In production deployments, the client and the server are on different machines, and in the case of the Python + Redis architecture, the feature store is yet another network hop away.
To demonstrate this, we spun up 3 EC2 instances and ran the benchmark again. This time, PostgresML outperformed Python and Redis by a factor of 40.
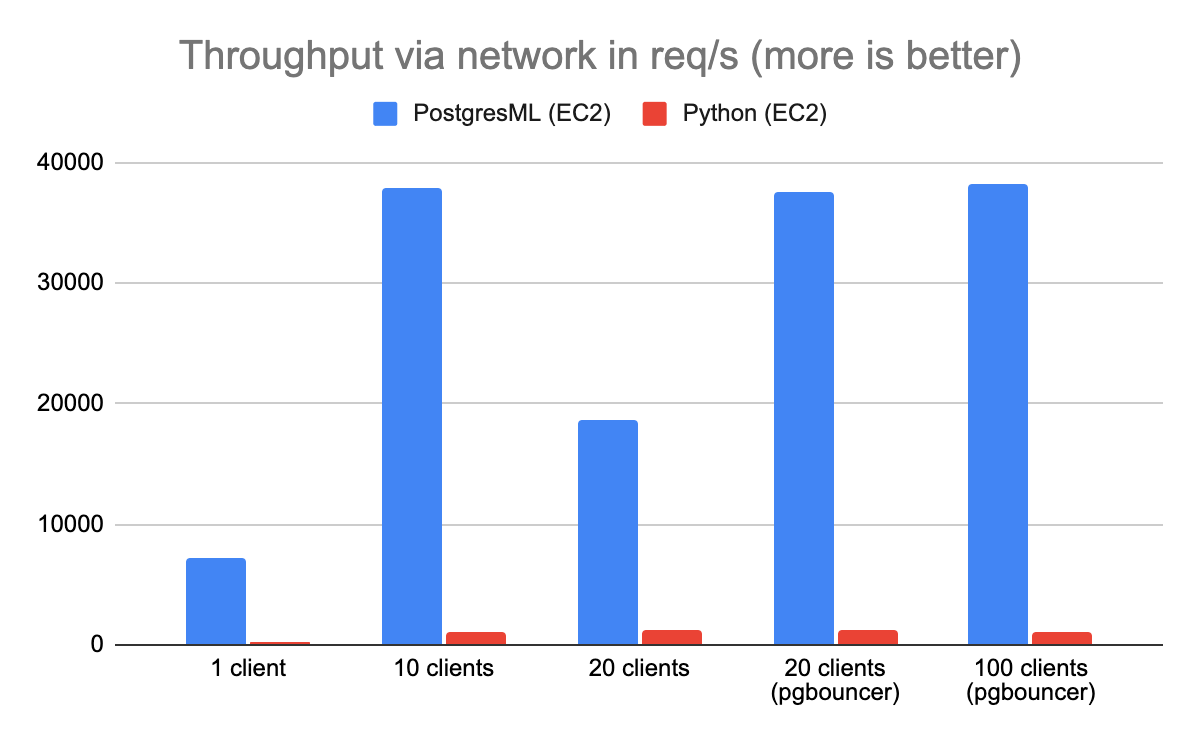
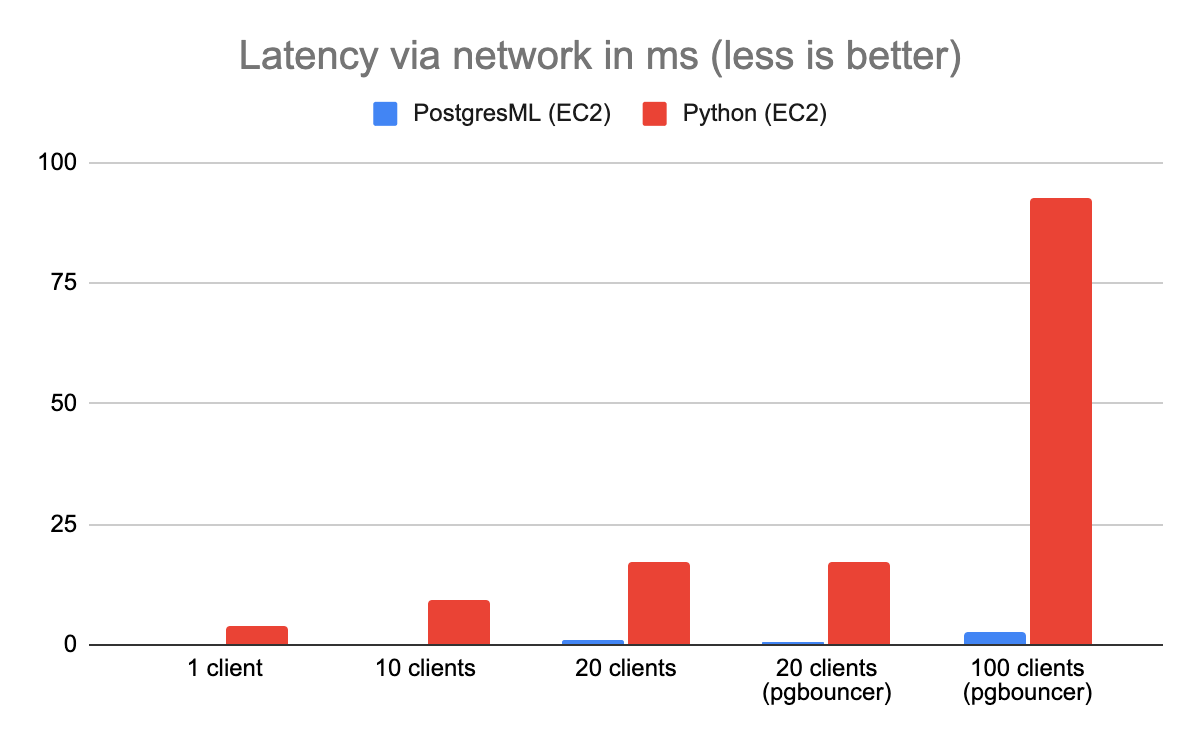
Network gap between Redis and Gunicorn made things worse...a lot worse. Fetching data from a remote feature store added milliseconds to the request the Python architecture could not spare. The additional latency compounded, and in a system that has finite resources, caused contention. Most Gunicorn threads were simply waiting on the network, and thousands of requests were stuck in the queue.
PostgresML didn't have this issue, because the features and the Rust inference layer live on the same system. This architectural choice removes network latency and (de)serialization from the equation.
You'll note the concurrency issue we discussed earlier hit Postgres at 20 connections, and we used PgBouncer again to save the day.
Scaling Postgres, once you know how to do it, isn't as difficult as it sounds.
Methodology
Hardware
Both the client and the server in the first benchmark were located on the same machine. Redis was local as well. The machine is an 8 core, 16 threads AMD Ryzen 7 5800X with 32GB RAM, 1TB NVMe SSD running Ubuntu 22.04.
AWS EC2 benchmarks were done with one c5.4xlarge instance hosting Gunicorn and PostgresML, and two c5.large instances hosting the client and Redis, respectively. They were located in the same VPC.
Configuration
Gunicorn was running with 5 workers and 2 threads per worker. Postgres was using 1, 5 and 20 connections for 1, 5 and 20 clients, respectively. PgBouncer was given a default_pool_size of 10, so a maximum of 10 Postgres connections were used for 20 and 100 clients.
XGBoost was allowed to use 2 threads during inference, and all available CPU cores (16 threads) during training.
Both ab and pgbench use all available resources, but are very lightweight; the requests were a single JSON object and a single query respectively. Both of the clients use persistent connections, ab by using HTTP Keep-Alives, and pgbench by keeping the Postgres connection open for the duration of the benchmark.
ML
Data
We used the Flight Status Prediction dataset from Kaggle. After some post-processing, it ended up being about 2 GB of floating point features. We didn't use all columns because some of them are redundant, e.g. airport name and airport identifier, which refer to the same thing.
Model
Our XGBoost model was trained with default hyperparameters and 25 estimators (also known as boosting rounds).
Data used for training and inference is available here. Data stored in the Redis feature store is available here. It's only a subset because it was taking hours to load the entire dataset into Redis with a single Python process (28 million rows). Meanwhile, Postgres COPY only took about a minute.
PostgresML model is trained with:
SELECT * FROM pgml.train(
project_name => 'r2',
algorithm => 'xgboost',
hyperparams => '{ "n_estimators": 25 }'
);
It had terrible accuracy (as did the Python version), probably because we were missing any kind of weather information, the latter most likely causing delays at airports.
Source code
Benchmark source code can be found on Github.