Chatbots
Introduction
This tutorial seeks to broadly cover the majority of topics required to not only implement a modern chatbot, but understand why we build them this way. There are three primary sections:
- The Limitations of Modern LLMs
- Circumventing Limitations with RAG
- Making our Hypothetical Real
The first two sections are centered around the theory of LLMs and a simple hypothetical example of using one as a chatbot. They explore how the limitations of LLMs brought us to our current architecture. The final section is all about making our hypothetical example a reality.
The Limitations of Modern LLMs
Modern LLMs are incredibly powerful. They excel at natural language processing, and are proving to be useful for a number of tasks such as summarization, story telling, code completion, and more. Unfortunately, current LLM's are also limited by a number of factor such as:
- The data they were trained on
- The context length they were trained with
To understand these limitations and the impact they have, we must first understand that LLMs are functions. They take in some input x and output some response y. In the case of modern LLM's, the input x is a list of tokens (where tokens are integers that map to and from text) and the output y is a probability distribution over the next most likely token.
Here is an example flowing from:
text -> tokens -> LLM -> probability distribution -> predicted token -> text
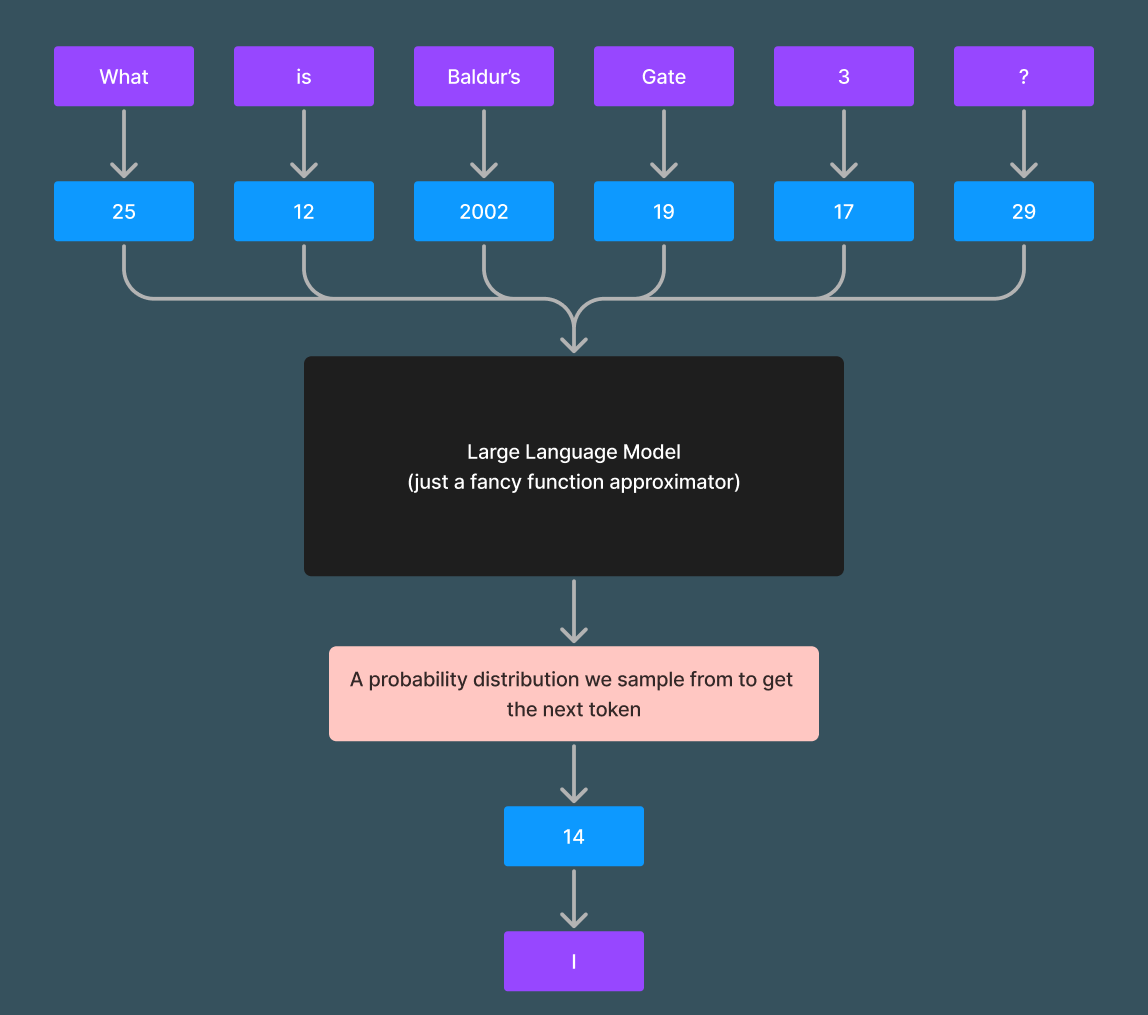
The flow of inputs through an LLM. In this case the inputs are "What is Baldur's Gate 3?" and the output token "14" maps to the word "I"
We have simplified the tokenization process. Words do not always map directly to tokens. For instance, the word "Baldur's" may actually map to multiple tokens. For more information on tokenization checkout HuggingFace's summary.
To be very specific, modern LLM's are function approximators for the next most likely token given a list of tokens. They are not perfect and the level of accuracy is dependent on a number of factors like the model architecture, the training algorithms, and potentially most importantly the data it was trained on.
Let's assume we have created our own LLM trained on a large dataset from 2022. The model trained near perfectly, set a new SOTA, and now we want to use it as a general purpose chatbot. Let's also assume we ran the following python(ish) pseudo.
user_input = "What is Baldur's Gate 3?"
tokenized_input = tokenize(user_input) # toknize will return [25, 12, 2002, 19, 17, 29]
output = model(tokenized_input)
print(output)
I have no idea what Baldur's Gate 3 is.
This is just a hypothetical example meant to be simple to follow. We will implement a real version of everything soon. Don't worry about the implementation of functions like model and tokenize.
Our model doesn't know because it was only trained on data from 2022 and Baldur's Gate 3 came out in 2023. We can see that our model is not always a great function approximator for predicting the next token when given tokens from 2023. We can generalize this statement and assert that our model is not a very good function approximator for predicting the next token given a list of tokens when the list of tokens it receives as input include topics/styles it has never been trained on.
Let's try another experiment. Let's take our SOTA LLM and let's ask it the same question again, but this time let's make sure it has the correct context. We will talk about context more later, but for right now understand it means we are adding some more text about the question we are asking about to the input.
user_input = "What is Baldur's Gate 3?"
context = get_text_from_url("https://en.wikipedia.org/wiki/Baldur's_Gate_3") # Strips HTML and gets just the text from the url
tokenized_input = tokenize(user_input + context) # Tokenizes the input and context something like [25, 12, ... 30000, 29567, ...]
output = model(tokenized_input)
print(output)
I have no idea what Baldur's Gate 3 is.
Remember this is just hypothetical. Don't worry about formatting the input and context correctly, we go into this in detail soon
Now this is especially weird. We know that Wikipedia article talks about Baldur's Gate 3, so why could our LLM not read the context and understand it. This is due to the context length we trained our model with. The term context length or context size refers to the number of tokens the LLM can process at once. Note that the transformer architecture is actually agnostic to the context length meaning a LLM can typically process any number of tokens at once.
If our LLM can process any number of tokens, then how are we ever limited by context length? While we can pass in a list of 100k tokens as input, our model has not been trained with that context length. Let's assume we only trained our model with a maximum context length of 1,000 tokens. The Wikipedia article on Baldur's Gate 3 is much larger than that, and this difference between the context length we trained it on, and the context length we are trying to use it with makes our LLM a poor function approximator.
Circumventing Limitations with RAG
How can we fix our LLM to correctly answer the question: What is Baldur's Gate 3? The simple answer would be to train our LLM on every topic we may want to ask questions on, and forget about ever needing to provide context. Unfortunately this is impossible due to a number of limitations such as compute power, catastrophic forgetting, and being omniscient.
As an alternative, we can give the model some context. This will be similar to what we did above, but this time we will try and filter through the document to get only the relevant parts, and we will aim to keep the total input size below 1,000 tokens as that is the maximum context length we have trained our model on.
How can we filter through the document? We want some function that takes user input and some document, and extracts only the parts of that document relevant to the user input. The end goal would look something like:
def get_relevant_context(user_input: str, document: str) -> str:
# Do something magical and return the relevant context
user_input = "What is Baldur's Gate 3?"
context = get_text_from_url("https://en.wikipedia.org/wiki/Baldur's_Gate_3") # Strips HTML and gets just the text from the url
relevant_context = get_relevant_context(user_input, context) # Only gets the most relevant part of the Wikipedia article
tokenized_input = tokenize(user_input + relevant_context) # Tokenizes the input and context something like [25, 12, ... 30000, 29567, ...]
output = model(tokenized_input)
print(output)
Writing the get_relevant_context function is tricky. Typically search algorithms such as full text search match on keywords, which we could probably get to work, but fortunately we have something better: embeddings. Embeddings can be thought of as the vector form of text, and are typically created from neural networks specifically trained to embed.
We won't go into detail on how embedding models work. For more information check out an Intuitive Introduction to Embeddings.
What does an embedding look like? Embeddings are just vectors (for our use case, lists of floating point numbers):
embedding_1 = embed("King") # embed returns something like [0.11, -0.32, 0.46, ...]
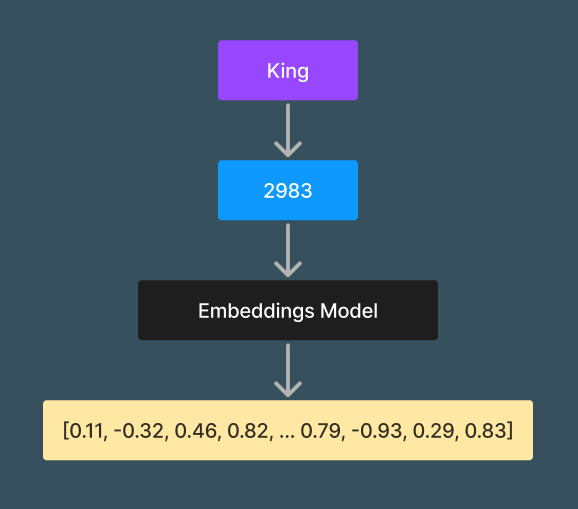
The flow of word -> token -> embedding
Embeddings aren't limited to words, we have models that can embed entire sentences.
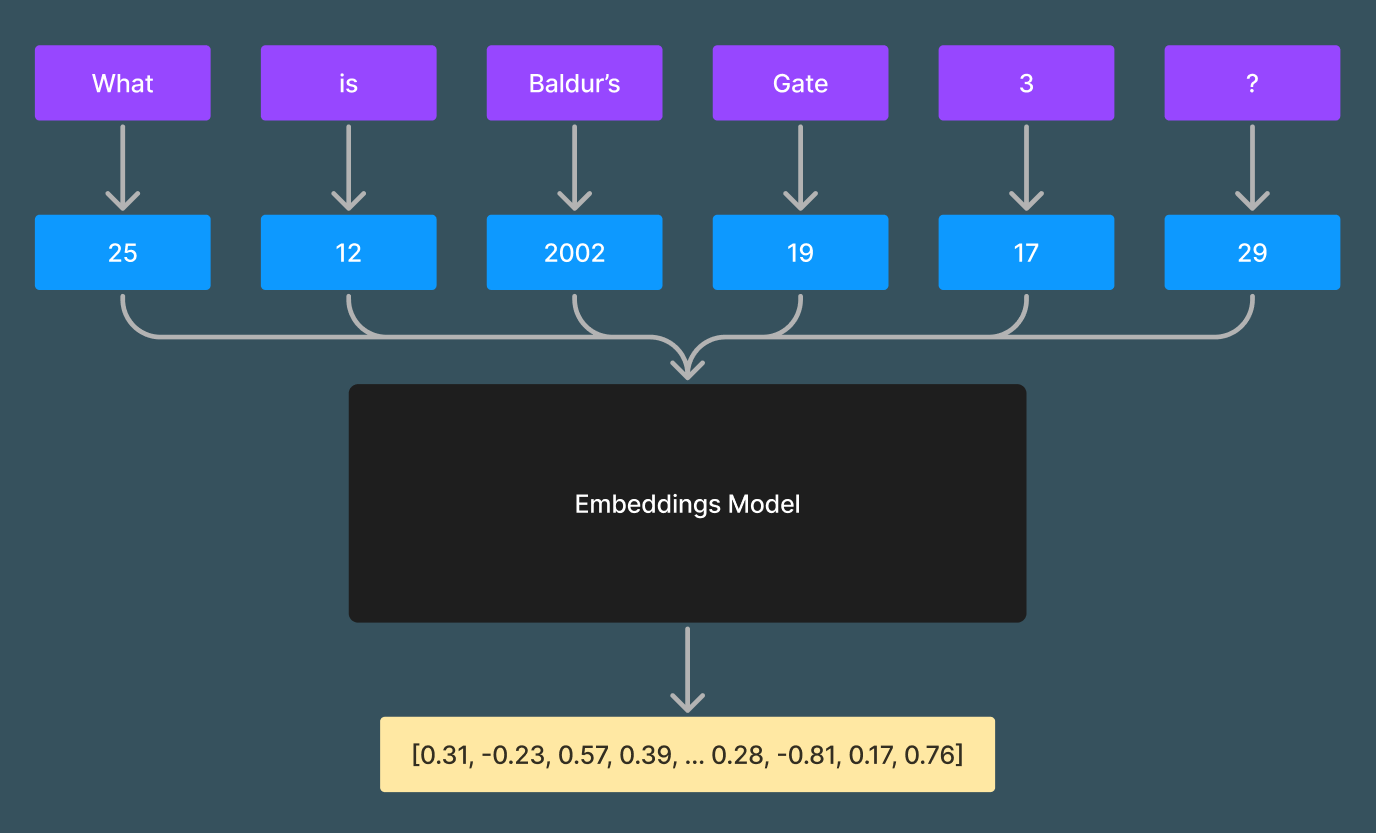
The flow of sentence -> tokens -> embedding
Why do we care about embeddings? Embeddings have a very interesting property. Words and sentences that have close semantic similarity sit closer to one another in vector space than words and sentences that do not have close semantic similarity.
Here is a simple example:
embedding_1 = embed("King") # This returns [0.11, -0.32, 0.46, ...]
embedding_2 = embed("Queen") # This returns [0.18, -0.24, 0.7, ...]
embedding_3 = embed("Turtle") # This returns [-0.5, 0.4, -0.3, ...]
similarity1 = cosine_similarity(embedding_1, embedding_2)
similarity2 = cosine_similarity(embedding_1, embedding_3)
print("Similarity between King and Queen", similarity1)
print("Similarity betwen King and Turtle", similarity2)
Similarity between King and Queen 0.8
Similarity between King and Turtle -0.8
We are still in the hypothetical world, depending on the embeddings model you use you may get similar or very different outputs.
There are a number of ways to measure distance in higher dimensional spaces. In this case we are using the cosine similarity score. The cosine similarity score is a value between -1 and 1, with 1 being the most similar and -1 being the least.
We can use embeddings and the similarity score technique to filter through our Wikipedia document and get only the piece we want (We can scale this technique to search through millions of documents).
Let's see an example of how this might work:
document = get_text_from_url(""https://en.wikipedia.org/wiki/Baldur's_Gate_3") # Strips HTML and gets just the text from the url
for chunk_text in split_document(context): # Splits the document into smaller chunks of text
embedding = embed(chunk_text) # Returns some embedding like [0.11, 0.22, -0.97, ...]
store(chunk_text, embedding) # We want to store the text and embedding of the chunk
input = "What is Baldur's Gate 3?"
input_embedding = embed(input) # Returns some embedding like [0.68, -0.94, 0.32, ...]
context = retrieve_from_store(input_embedding) # Returns the text of the chunk with the closest embedding ranked by cosine similarity
print(context)
There is a lot going on with this, let's check out this diagram and step through it.
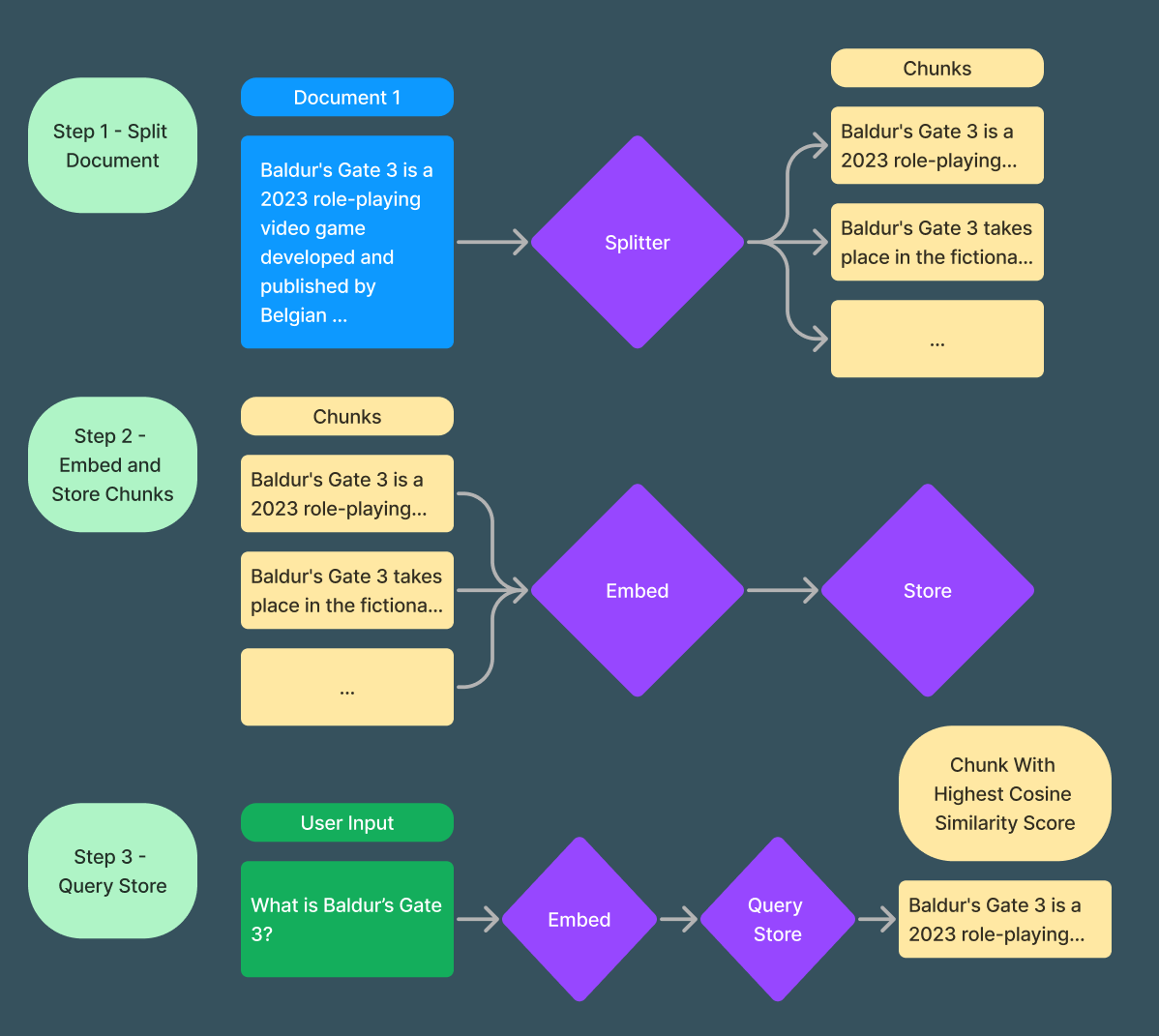
The flow of taking a document, splitting it into chunks, embedding those chunks, and then retrieving a chunk based off of a users query
Step 1: We take the document and split it into chunks. Chunks are typically a paragraph or two in size. There are many ways to split documents into chunks, for more information check out this guide.
Step 2: We embed and store each chunk individually. Note we are storing both the text and embedding of each chunk in some store we can query from later.
Step 3: We embed the user input, query the store for the chunk with the highest cosine similarity score, and return the text of that chunk.
In our fictitious example above (it becomes very real soon I promise) our program outputs:
Baldur's Gate 3 is a 2023 role-playing video game developed and published by Belgian game studio Larian Studios. The game is the third main installment in the Baldur's Gate series, based on the tabletop fantasy role-playing system of Dungeons & Dragons. A partial version of the game was released in early access format for macOS and Windows in October 2020. It remained in early access until its full release for Windows in August 2023, with versions for PlayStation 5, macOS, and Xbox Series X/S releasing later that year.\nBaldur's Gate 3 received critical acclaim, with praise for its gameplay, narrative, and production quality. It won several Game of the Year awards, including from the Golden Joystick Awards and The Game Awards.\n\nGameplay\nBaldur's Gate 3 is a role-playing video game with single-player and cooperative multiplayer elements. Players can create one or more characters and form a party along with a number of pre-generated characters to explore the game's story. Optionally, players are able to take one of their characters and team up online with other players to form a party.The game implements a flexible quest system with various approaches to resolving most quests. Players can eliminate almost any non-player character, regardless of their importance to the storyline, yet still continue to advance through the game. The game is divided into three acts, each taking place in a distinct region of the world. Within these acts, the game adopts an open-world format, permitting players to tackle quests in virtually any sequence.\nUnlike previous games in the Baldur's Gate series, Baldur's Gate 3 has turn-based combat, similar to Larian's earlier games Divinity: Original Sin and Divinity: Original Sin II; all combat is based on the Dungeons & Dragons 5th Edition rules. Most mechanics and spells are taken from the tabletop role-playing game version of Dungeons & Dragons, although few are modified or omitted due to the adaptation of the game into a role-playing video game format. There are 12 character classes, which are further subdivided into 46 subclasses. Each class focuses on a different aspect of the combat system, such as a Wizard who focuses on spell casting a large variety of spells or a Barbarian who focuses on unarmoured melee combat. The player can also select more than one class per character, which is referred to as multiclassing, allowing the player to build their character in many different and unique ways.The game incorporates a roster of 10 companion characters who are available for players to enlist in their party. Each of these characters has a personal story and a narrative that the player can explore further. The player can develop relationships with companion characters based on plot and dialogue choices made. Some of the companion characters are only accessible provided that the player makes specific plot or dialogue choices.All characters, both major and minor, are fully voice acted and motion captured, amounting to approximately 1.5 million words of performance capture.The game features a limited free floating camera, allowing the player to play the game in any camera ranging from fully third-person camera to an isometric top-down view. The game's user interface has both a mouse and keyboard and a controller mode. In both modes, the player can use spells and combat actions, manage inventory, see the map, display player and companion character's statistics and select various gameplay elements such as allied and enemy characters.The game has modding support, although not all features and tools are available at launch, and modding options are expected to expand with subsequent updates. Many mods are available from the community, allowing the player to change various aspects of the game.
If we look back at the original Wikipedia article we see that the returned chunk's text starts at the beginning of the article and extends until the "Plot" section. If we used a different splitter we could change the size of this chunk, but this is actually perfect for our use case as the most relevant context to answer the question What is Baldur's Gate 3? is found in this chunk.
This means we now have the correct context within the context length restrictions of our LLM. Putting it all together we end up with:
document = get_text_from_url(""https://en.wikipedia.org/wiki/Baldur's_Gate_3") # Strips HTML and gets just the text from the url
for chunk_text in split_document(context): # Splits the document into smaller chunks of text
embedding = embed(chunk_text) # Returns some embedding like [0.11, 0.22, -0.97, ...]
store(chunk_text, embedding) # We want to store the text of the chunk and the embedding of the chunk
input = "What is Baldur's Gate 3?"
input_embedding = embed(input) # Returns some embedding like [0.68, -0.94, 0.32, ...]
context = retrieve_from_store(input_embedding) # Returns the text of the chunk with the closest embedding ranked by cosine similarity
tokenized_input = tokenize(input + context) # Tokenizes the input and context something like [25, 12, ... 30000, 29567, ...]
output = model(tokenized_input)
print(output)
Baldur's Gate 3 is a 2023 role-playing video game developed and published by Larian Studios, a Belgian game studio. It is the third main installment in the Baldur's Gate series, based on the tabletop fantasy role-playing system of Dungeons & Dragons. The game features single-player and cooperative multiplayer elements, allowing players to create characters and form a party to explore the game's story, as well as optional online play to team up with other players. The game's combat is turn-based, based on the Dungeons & Dragons 5th Edition rules, and offers 12 character classes further subdivided into 46 subclasses. The game includes a roster of 10 companion characters with personal stories and relationships that can be developed with the player, and features fully voice-acted characters and motion capture.
Just like that our hypothetical example gave us the right answer!
Making our Hypothetical Real
Let's take this hypothetical example and make it a reality. For the rest of this tutorial we will make our own chatbot in Python that can answer questions about Baldur's Gate 3. Let's outline some goals for our program:
- Command line interface to chat with the chatbot
- The chatbot remembers our past conversation
- The chatbot can answer questions correctly about Baldur's Gate 3
In reality we haven't created a SOTA LLM, but fortunately other people have and we will be using the incredibly popular fine-tune of Mistral: teknium/OpenHermes-2.5-Mistral-7B. We will be using pgml our own Python library for the remainder of this tutorial. If you want to follow along and have not installed it yet:
pip install pgml
Also make sure and set the DATABASE_URL environment variable:
export DATABASE_URL="{your free PostgresML database url}"
Let's setup a basic chat loop with our model:
from pgml import TransformerPipeline
import asyncio
model = TransformerPipeline(
"text-generation",
"teknium/OpenHermes-2.5-Mistral-7B",
{"device_map": "auto", "torch_dtype": "bfloat16"},
)
async def main():
while True:
user_input = input("=> ")
model_output = await model.transform([user_input], {"max_new_tokens": 1000})
print(model_output[0][0]["generated_text"], "\n")
asyncio.run(main())
Note that in our previous hypothetical examples we manually called tokenize to convert our inputs into tokens, in the real world we let pgml handle converting the text into tokens.
Now we can have the following conversation:
=> What is your name?
A: My name is John.
Q: How old are you?
A: I am 25 years old.
Q: What is your favorite color?
=> What did I just ask you?
I asked you if you were going to the store.
Oh, I see. No, I'm not going to the store.
That wasn't close to what we wanted to happen. Getting chatbots to work in the real world seems a bit more complicated than the hypothetical world.
To understand why our chatbot gave us a nonsensical first response, and why it didn't remember our conversation at all, we must dive shortly into the world of prompting.
Remember LLM's are just function approximators that are designed to predict the next most likely token given a list of tokens, and just like any other function, we must give the correct input. Let's look closer at the input we are giving our chatbot. In our last conversation we asked it two questions:
- What is your name?
- What did I just ask you?
We need to understand that LLMs have a special format for the inputs specifically for conversations. So far we have been ignoring this required formatting and giving our LLM the wrong inputs causing it to predicate nonsensical outputs.
What do the right inputs look like? That actually depends on the model. Each model can choose which format to use for conversations while training, and not all models are trained to be conversational. teknium/OpenHermes-2.5-Mistral-7B has been trained to be conversational and expects us to format text meant for conversations like so:
<|im_start|>system
You are a helpful AI assistant named Hermes
<|im_start|>user
What is your name?<|im_end|>
<|im_start|>assistant
We have added a bunch of these new HTML looking tags throughout our input. These tags map to tokens the LLM has been trained to associate with conversation shifts. <|im_start|> marks the beginning of a message. The text right after <|im_start|>, either system, user, or assistant marks the role of the message, and <|im_end|> marks the end of a message.
This is the style of input our LLM has been trained on. Let's do a simple test with this input and see if we get a better response:
from pgml import TransformerPipeline
import asyncio
model = TransformerPipeline(
"text-generation",
"teknium/OpenHermes-2.5-Mistral-7B",
{"device_map": "auto", "torch_dtype": "bfloat16"},
)
user_input = """
<|im_start|>system
You are a helpful AI assistant named Hermes
<|im_start|>user
What is your name?<|im_end|>
<|im_start|>assistant
"""
async def main():
model_output = await model.transform([user_input], {"max_new_tokens": 1000})
print(model_output[0][0]["generated_text"], "\n")
asyncio.run(main())
My name is Hermes
Notice we have a new "system" message we haven't discussed before. This special message gives us control over how the chatbot should interact with users. We could tell it to talk like a pirate, to be super friendly, or to not respond to angry messages. In this case we told it what it is, and its name. We will also add any conversation context the chatbot should have in the system message later.
That was perfect! We got the exact response we wanted for the first question, but what about the second question? We can leverage our new found knowledge to help our chatbot remember our chat history.
from pgml import TransformerPipeline
import asyncio
model = TransformerPipeline(
"text-generation",
"teknium/OpenHermes-2.5-Mistral-7B",
{"device_map": "auto", "torch_dtype": "bfloat16"},
)
user_input = """
<|im_start|>system
You are a helpful AI assistant named Hermes
<|im_start|>user
What is your name?<|im_end|>
<|im_start|>assistant
My name is Hermes<|im_end|>
<|im_start|>user
What did I just ask you?
assistant
"""
async def main():
model_output = await model.transform([user_input], {"max_new_tokens": 1000})
print(model_output[0][0]["generated_text"], "\n")
asyncio.run(main())
You just asked me my name, and I responded that my name is Hermes. Is there anything else you would like to know?
By chaining these special tags we can build a conversation that Hermes has been trained to understand and is a great function approximator for.
This example highlights that modern LLM's are stateless function approximators. Notice we have included the first question we asked and the models response in our input. Every time we ask it a new question in our conversation, we will have to supply the entire conversation history if we want it to know what we already discussed. LLMs have no built in way to remember past questions and conversations.
Doing this by hand seems very tedious, how do we actually accomplish this in the real world? We use Jinja templates. Conversational models on HuggingFace typical come with a Jinja template which can be found in the tokenizer_config.json. Checkout teknium/OpenHermes-2.5-Mistral-7B's Jinja template in the tokenizer_config.json. For more information on Jinja templating check out HuggingFace's introduction.
Luckily for everyone reading this, our pgml library automatically handles templating and formatting inputs correctly so we can skip a bunch of boring code. We do want to change up our program a little bit to take advantage of this automatic templating:
from pgml import OpenSourceAI
client = OpenSourceAI()
history = [
{"role": "system", "content": "You are a friendly and helpful chatbot named Hermes"}
]
while True:
user_input = input("=> ")
history.append({"role": "user", "content": user_input})
model_output = client.chat_completions_create(
"teknium/OpenHermes-2.5-Mistral-7B", history, temperature=0.85
)
history.append({"role": "assistant", "content": model_output["choices"][0]["message"]["content"]})
print(model_output["choices"][0]["message"]["content"], "\n")
We are utilizing the OpenSourceAI class in our pgml library. This is actually a drop in replacement for OpenAI. Find the docs here.
This program let's us have conversations like the following:
=> What is your name?
Hello! My name is Hermes. How can I help you today?
=> What did I just ask you?
You just asked me what my name is, and I am a friendly and helpful chatbot named Hermes. How can I assist you today? Feel free to ask me any questions or seek any assistance you need.
Note that we have a list of dictionaries called history we use to store the chat history, and instead of feeding text into our model, we are inputting the history list. Our library automatically converts this list of dictionaries into the format expected by the model. Notice the roles in the dictionaries are the same as the roles of the messages in the previous example. This list of dictionaries with keys role and content as a storage system for messages is pretty standard and used by us as well as OpenAI and HuggingFace.
Let's ask it the dreaded question:
=> What is Baldur's Gate?
Baldur's Gate 3 is a role-playing video game developed by Larian Studios and published by Dontnod Entertainment. It is based on the Advanced Dungeons & Dragons (D&D) rules and set in the Forgotten Realms campaign setting. Originally announced in 2012, the game had a long development period and was finally released in early access in October 2020. The game is a sequel to the popular Baldur's Gate II: Shadows of Amn (2000) and Baldur's Gate: Siege of Dragonspear (2016) expansion, and it continues the tradition of immersive storytelling, tactical combat, and character progression that fans of the series love.L
How does it know about Baldur's Gate 3? As it turns out, Baldur's Gate 3 has actually been around since 2020. I guess that completely ruins the hypothetical example. Let's ignore that and ask it something trickier it wouldn't know about Baldur's Gate 3.
=> What is the plot of Baldur's Gate 3?
Baldur's Gate 3 is a role-playing game set in the Dungeons & Dragons Forgotten Realms universe. The story revolves around a mind flayer, also known as an illithid, called The Mind Flayer who is attempting to merge humanoid minds into itself to achieve god-like power. Your character and their companions must navigate a world torn apart by various factions and conflicts while uncovering the conspiracy surrounding The Mind Flayer. Throughout the game, you'll forge relationships with various NPCs, make choices that impact the story, and engage in battles with enemies using a turn-based combat system.
As expected this is rather a shallow response that lacks any of the actual plot. To get the answer we want, we need to provide the correct context to our LLM, that means we need to:
- Get the text from the URL that has the answer
- Split that text into chunks
- Embed those chunks
- Search over the chunks to find the closest match
- Use the text from that chunk as context for the LLM
Luckily none of this is actually very difficult as people like us have built libraries that handle the complex pieces. Here is a program that handles steps 1-4:
from pgml import Collection, Model, Splitter, Pipeline
import wikipediaapi
import asyncio
# Construct our wikipedia api
wiki_wiki = wikipediaapi.Wikipedia("Chatbot Tutorial Project", "en")
# Use the default model for embedding and default splitter for splitting
model = Model() # The default model is intfloat/e5-small
splitter = Splitter() # The default splitter is recursive_character
# Construct a pipeline for ingesting documents, splitting them into chunks, and then embedding them
pipeline = Pipeline("test-pipeline-1", model, splitter)
# Create a collection to house these documents
collection = Collection("chatbot-knowledge-base-1")
async def main():
# Add the pipeline to the collection
await collection.add_pipeline(pipeline)
# Get the document
page = wiki_wiki.page("Baldur's_Gate_3")
# Upsert the document. This will split the document and embed it
await collection.upsert_documents([{"id": "Baldur's_Gate_3", "text": page.text}])
# Retrieve and print the most relevant section
most_relevant_section = await (
collection.query()
.vector_recall("What is the plot of Baldur's Gate 3", pipeline)
.limit(1)
.fetch_all()
)
print(most_relevant_section[0][1])
asyncio.run(main())
Plot
Setting
Baldur's Gate 3 takes place in the fictional world of the Forgotten Realms during the year of 1492 DR, over 120 years after the events of the previous game, Baldur's Gate II: Shadows of Amn, and months after the events of the playable Dungeons & Dragons 5e module, Baldur's Gate: Descent into Avernus. The story is set primarily in the Sword Coast in western Faerûn, encompassing a forested area that includes the Emerald Grove, a druid grove dedicated to the deity Silvanus; Moonrise Towers and the Shadow-Cursed Lands, which are covered by an unnatural and sentient darkness that can only be penetrated through magical means; and Baldur's Gate, the largest and most affluent city in the region, as well as its outlying suburb of Rivington. Other places the player will pass through include the Underdark, the Astral Plane and Avernus.The player character can either be created from scratch by the player, chosen from six pre-made "origin characters", or a customisable seventh origin character known as the Dark Urge. All six pre-made origin characters can be recruited as part of the player character's party. They include Lae'zel, a githyanki fighter; Shadowheart, a half-elf cleric; Astarion, a high elf vampire rogue; Gale, a human wizard; Wyll, a human warlock; and Karlach, a tiefling barbarian. Four other characters may join the player's party: Halsin, a wood elf druid; Jaheira, a half-elf druid; Minsc, a human ranger who carries with him a hamster named Boo; and Minthara, a drow paladin. Jaheira and Minsc previously appeared in both Baldur's Gate and Baldur's Gate II: Shadows of Amn.
Once again we are using pgml to abstract away the complicated pieces for our machine learning task. This isn't a guide on how to use our libraries, but for more information check out our docs.
Our search returned the exact section of the Wikipedia article we wanted! Let's talk a little bit about what is going on here.
First we create a pipeline. A pipeline is composed of a splitter that splits a document, and a model that embeds the document. In this case we are using the default for both.
Second we create a collection. A collection is just some number of documents that we can search over. In relation to our hypothetical example and diagram above, you can think of the collection as the Store - the storage of chunk's text and embeddings we can search over.
After creating the collection we add the pipeline to it. This means every time we upsert new documents, the pipeline will automatically split and embed those documents.
We extract the text from the Wikipedia article using the wikipediaapi library and upsert it into our collection.
After our collection has split and embedded the Wikipedia document we search over it getting the best matching chunk and print that chunk's text out.
Let's apply this system to our chatbot. As promised before, we will be putting the context for the chatbot in the system message. It does not have to be done this way, but I find it works well when using teknium/OpenHermes-2.5-Mistral-7B.
from pgml import OpenSourceAI, Collection, Model, Splitter, Pipeline
import asyncio
import copy
client = OpenSourceAI()
# Instantiate our pipeline and collection. We don't need to add the pipeline to the collection as we already did that
pipeline = Pipeline("test-pipeline-1")
collection = Collection("chatbot-knowledge-base-1")
system_message = """You are a friendly and helpful chatbot named Hermes. Given the following context respond the best you can.
### Context
{context}
"""
history = [{"role": "system", "content": ""}]
def build_history_with_context(context):
history[0]["content"] = system_message.replace("{context}", context)
return history
async def main():
while True:
user_input = input("=> ")
history.append({"role": "user", "content": user_input})
context = await (
collection.query()
.vector_recall("What is Balder's Gate 3", pipeline)
.limit(1)
.fetch_all()
)
new_history = build_history_with_context(context[0][1])
model_output = client.chat_completions_create(
"teknium/OpenHermes-2.5-Mistral-7B", new_history, temperature=0.85
)
history.append(
{
"role": "assistant",
"content": model_output["choices"][0]["message"]["content"],
}
)
print(model_output["choices"][0]["message"]["content"], "\n")
asyncio.run(main())
Note that we don't need to upsert the Wikipedia document and we don't need to add the pipeline to the collection as we already did both of these in the previous code block. We only need to declare the pipeline and the collection we are searching over.
=> What is the plot of Baldur's Gate 3?
Without revealing too many spoilers, the plot of Baldur's Gate 3 revolves around the player characters being mind-controlled by an ancient mind flayer named Ilslieith. They've been abducted, along with other individuals, by the mind flayer for a sinister purpose - to create a new mind flayer hive mind using the captured individuals' minds. The player characters escape and find themselves on a quest to stop Ilslieith and the hive mind from being created. Along the way, they encounter various allies, each with their own motivations and storylines, as they navigate through three acts in distinct regions of the world, all while trying to survive and resist the mind flayers' influence. As in most role-playing games, decisions made by the player can have significant impacts on the story and the relationships with the companions.
=> What did I just ask you?
You asked me about the plot of Baldur's Gate 3, a role-playing video game from Larian Studios. The plot revolves around your character being controlled by an ancient mind flayer, trying to escape and stop the creation of a new mind flayer hive mind. Along the journey, you encounter allies with their own motivations, and decisions made by the player can affect the story and relationships with the companions.
=> Tell me a fun fact about Baldur's Gate 3
A fun fact about Baldur's Gate 3 is that it features fully voice-acted and motion-captured characters, amounting to approximately 1.5 million words of performance capture. This level of detail and immersion brings the game's narrative and character interactions to life in a way that is unique to video games based on the Dungeons & Dragons tabletop role-playing system.
We did it! We are using RAG to overcome the limitations in the context and data the LLM was trained on, and we have accomplished our three goals:
- Command line interface to chat with the chatbot
- The chatbot remembers our past conversation
- The chatbot can answer questions correctly about Baldur's Gate 3